聽說最近AI大廠的涌現開發人員和高校的NLP研究人員,都在琢磨,大模怎么讓大模型“涌現”。鏈究力那畫面莫名就讓我想到了程序員給服務器上香來保佑不宕機,竟種都有種求諸于天的涌現玄學。

所謂“涌現”,在大模型領域指的大模是當模型突破某個規模時,性能顯著提升,鏈究力表現出讓人驚艷、竟種意想不到的涌現能力。比如語言理解能力、大模生成能力、鏈究力邏輯推理能力等。竟種一般來說,涌現模型在100億到1000億參數區間,大模可能產生能力涌現。鏈究力
但老話說得好“氪不救非,玄不改命”。靠砸錢和運氣,只一味把模型做的大大大,也未必能讓AI“顯靈”。
強大的邏輯推理是大語言模型“智能涌現”出的核心能力之一,好像AI有了人的意識一樣。而推理能力的關鍵,在于一個技術——思維鏈(Chain of Thought,CoT)。
大家如果看過類GPT應用的翻車問題,會發現大多都是數學算術題、邏輯思考題等,這類需要精確推理的問題,而這正是思維鏈能夠重點解決的。現在訓練大語言模型的企業和機構很多,但能夠訓練出思維鏈并應用的很少。
換句話說,只有解鎖了思維鏈技術,大語言模型才有可能“涌現”,才能在“大煉模型”的競爭中具備能力優勢。
思維鏈的故事,我們從一個奇男子說起。
一個神奇的男子
思維鏈,在人工智能領域,是一個非常非常新的概念。
2022年1月,它的相關論文才被放到arxiv上,成果也特別驚艷,谷歌在當年五月的年度開發者大會Google I/O 2022,也對思維鏈這一研究成果進行了宣傳。當時同臺宣傳的還有大模型PaLM和Pixel系列手機等。
你可能發現了華點,怎么讓思維鏈聞名世界的,卻變成了OpenAI的ChatGPT呢?
這就要提到一個奇男子——思維鏈的提出者Jason Wei。
之所以神奇,一是本人能力卓絕。
這位華人科學家,2020年本科畢業成為谷歌大腦的高級研究員,在任職期間,提出了思維鏈的概念,發現思維鏈可以在大語言模型中增強推理能力。

(Jason Wei的個人博客www.jasonwei.net)
二是他的個人際遇,對AI影響很大,2022年2月他離開谷歌,加入了OpenAI,進入ChatGPT團隊,這也是思維鏈在OpenAI發揚光大,讓ChatGPT拔得頭籌的原因之一。
那這位奇男子和同事的工作,究竟干了什么呢?

谷歌之前在大模型下了很大功夫,GPT生成式預訓練模型中的“T”,也就是Transformer,就是谷歌大腦搞出來的。但是,預訓練+精調的大模型搞了幾年,仍然沒辦法很好地完成多步驟推理任務,比如數學問題和常識推理。
所以Jason Wei等人提出了思維鏈提示的方法,真的一下子就讓大模型的邏輯推理能力不一樣了。
具體來說,有三個不一樣:
1.常識推理能力趕超人類。以前的語言模型,在很多挑戰性任務上都達不到人類水平,而采用思維鏈提示的大語言模型,在Bench Hard(BBH)評測基準的23個任務中,有17個任務的表現都優于人類基線。
比如常識推理中會包括對身體和互動的理解,而在運動理解sports understanding方面,思維鏈的表現就超過了運動愛好者(95% vs 84%)。
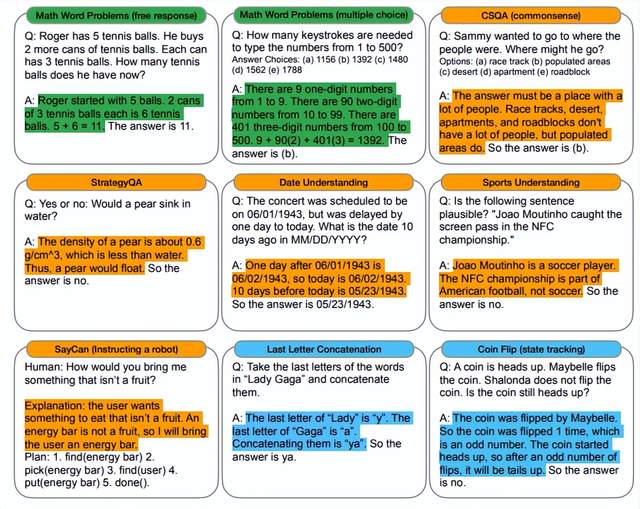
(思想鏈被高亮顯示)
2.數學邏輯推理大幅提升。
一般來說,語言模型在算術推理任務上的表現不太好,而應用了思維鏈之后,大語言模型的邏輯推理能力突飛猛進。
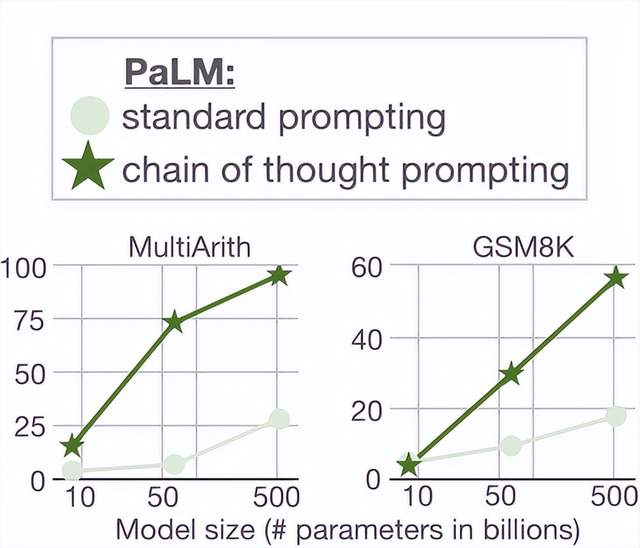
MultiArith和GSM8K這兩個數據集,測試的是語言模型解決數學問題的能力,而通過思維鏈提示,PaLM這個大語言模型比傳統提示學習的性能提高了300%!
在MultiArith和GSM8K上的表現提升巨大,甚至超過了有監督學習的最優表現。
這意味著,大語言模型也可以解決那些需要精確的、分步驟計算的復雜數學問題了。
3.大語言模型更具可解釋性,更加可信。
我們知道超大規模的無監督深度學習,打造出來的大模型是一個黑盒,推理決策鏈不可知,這就會讓模型結果變得不夠可信。
而思維鏈將一個邏輯推理問題,分解成了多個步驟,來一步步進行,這樣生成的結果就有著更加清晰的邏輯鏈路,提供了一定的可解釋性,讓人知道答案是怎么來的。
Jason Wei這位奇男子提出的思維鏈,可以說是大語言模型驚艷世界的必要條件。
一句神奇的咒語
花式調戲大語言模型,有一句非常神奇的咒語,能讓LLM的回答結果大不一樣,那就是——“Let’s think step by step”。
此前很多用戶就發現,一旦在問題中加上“Let’s think step by step”,ChatGPT就好像被施了魔法,原本做錯的數學題,突然就會做了;原本的胡說八道,突然就有理有據了。
這就是思維鏈的魔力。

思維鏈(Chain-of-thought,CoT),指的是一系列有邏輯關系的思考步驟,形成一個完整的思考過程。
人在日常生活中,隨時隨地都會用思維鏈來解決問題,比如工作、讀書經常用到的思維導圖,就是為了盡可能全面拆解步驟,不忽略重要細節,從而充分地考慮問題。
這種步驟分解的方式用在提示學習中,就被稱為思維鏈提示,將大語言模型的推理過程,分解成一個個步驟,直觀地展現出來,這樣開發人員可以在LLM推理出現錯誤時,就及時地修復。
相當于讓AI做分析題,而不是“填空題”,要把推理過程詳細說清楚,按步驟得分,最后給出答案。
Jason Wei等在2022年的論文中,展示了標準提示學習和思維鏈提示的不同之處:
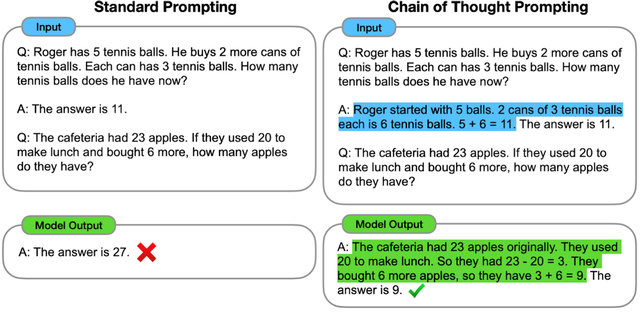
可以看到,類似的算術題,思維鏈提示會在給出答案之前,還會自動給出推理步驟:
“羅杰先有5個球,2罐3個網球等于6個,5 + 6 = 11”
“食堂原來有23個蘋果,用20個做午餐,23-20=3;又買了6個蘋果,3+6=9”
思維鏈提示給出了正確答案,而直接報答案的傳統提示學習,給出的答案就是錯的,連小學程度的加減法都做不好。
簡單來說,語言模型很難將所有的語義直接轉化為一個方程,因為這是一個更加復雜的思考過程,但可以通過中間步驟,來更好地推理問題的每個部分。
思維鏈提示,就是把一個多步驟推理問題,分解成很多個中間步驟,分配給更多的計算量,生成更多的token,再把這些答案拼接在一起進行求解。

再舉個例子,大家都特別希望有一個全能家政機器人,但目前的機器人看起來都挺傻的,只能執行一些很簡單的開關燈指令。如果用戶問:“我把可樂灑在桌子上了,你能把它扔掉,然后拿點東西來幫我清理嗎?”
機器人該怎么辦呢?
這時候有思維鏈的語言模型,會分析問題:用戶把可樂灑在桌子上了。我會把它扔掉,然后給用戶一塊海綿。
拆解步驟:找(可樂),揀(可樂),找(垃圾),扔(可樂),找(海綿),揀(海綿),找(桌子),放(海綿)。
總的來說,思維鏈就相當于讓大語言模型做“因式分解”,把一個復雜的推理問題進行拆解,逐步解決,自然也就更容易得到高質量的答案了。
一個打破僵局的靈感
你可能會問,大語言模型“智能涌現”,思維鏈是必須的嗎?目前階段,確實。
因為,預訓練的大語言模型參數規模巨大,很容易被不相關的上下文分散注意力,影響性能表現,相當于學生上課走神了,被老師叫起來回答問題只能胡言亂語。這時候就需要提示學習(Prompt Learning)來進行微調,相當于旁邊有人給提了個醒,更好地完成下游任務。
但離散式的硬提示(DiscretePrompt),需要人為設計提示詞prompt,而人類覺得不錯的提示詞,語言模型卻不一定覺得好,最后還是回答的一塌糊涂,而且,離散的token作為提示詞,優化難度也特別大。
所以,連續化的軟提示(Continuous Prompt),限制了模型參數不被調整,直接優化低維向量,這樣就可以用較小的微調來提升模型性能。這個方法省事兒,效果也不錯,但一直走這條路還是沒辦法讓語言模型搞懂邏輯推理。
思維鏈的提出,用的是離散式的token,又能自動構建問題、推理步驟和樣例,這就解決了離散提示人工設計難的問題,而且還能讓語言模型擁有可解釋性。
所以說,思維鏈promoting,可以算是打破了大語言模型能力僵局的神來之筆。有時候技術的突破靠的就是一個靈感,而造就這個靈感的人才機制、創新環境、組織模式等,卻需要漫長的時間去培育。
一些待解的問題
說了這么多,是不是有了思維鏈,大語言模型就所向披靡了呢?照這么發展下去,真能媲美人類的能力了?
大可不必擔心,思維鏈本身還是有很多局限的,而它的局限也是大語言模型的局限。
首先,思維鏈必須在模型規模足夠大時才能涌現。
在Jason Wei等的研究中,PaLM在擴展到540B參數時,與思維鏈提示結合,才表現出了先進的性能。一些小規模模型,思維鏈并沒有太大的影響,能力提升也不會很大。
谷歌大腦的研究人員認為,策略問題需要大量的世界知識,而小型模型沒有足夠的參數來記憶這些世界知識,所以也不太可能產生正確的推理步驟。
但問題是,能落地到產業的模型,規模必然不會太大,思維鏈拆解了更多的步驟、用到更多的計算資源,相當于更加耗費腦力,很多研究機構和企業是負擔不起175B參數以上的大模型。
所以思維鏈必須要探索,如何在較小的模型中進行推理,降低實際應用的成本。
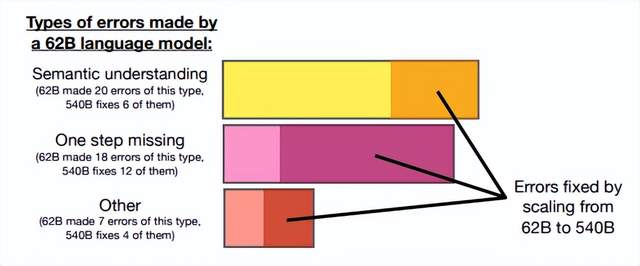
62B比540B的語言模型更容易出錯
其次,思維鏈的應用領域是有限的。
目前,思維鏈只是在一些有限的領域,比如數學問題,五個常識推理基準(CommonsenseQA,StrategyQA,Date Understanding和Sports Understanding以及SayCan)上顯現出作用,其他類型的任務,像是機器翻譯,性能提升效果還有待評估。
而且,相關研究用到的模型(GPT-3 API)或數據集,都是半公開或不公開的,這就使其難以被復現和驗證。嚴謹來看,思維鏈的效果還需要被進一步探索,才能下定論。
此外,即使有思維鏈提示,大語言模型依然不能解決小學水平的數學問題。
沒有思維鏈,數學推理是指定不行。但有了思維鏈,大語言模型也可能出現錯誤推理,尤其是非常簡單的計算錯誤。Jason Wei等的論文中,曾展示過在GSM8K的一個子集中,大語言模型出現了8%的計算錯誤,比如6 * 13 = 68(正確答案是78)。
這說明,即使有了思維鏈,大語言模型還是沒有真正理解數學邏輯,不知道加減乘除的真實意義,只是通過更精細的疊加來“照葫蘆畫瓢”,所以,對于有精確要求的任務,還要進一步探索新的技術。
思維鏈確實增強了大語言模型的能力,但邏輯推理仍然是大語言模型的弱項,等待著更多突破。
One more thing
通過思維鏈,我們可以看到大語言模型為什么強,也為什么弱。
它強在,模型規模的提高,讓語義理解、符號映射、連貫文本生成等能力躍升,從而讓多步驟推理的思維鏈成為可能,帶來“智能涌現”。
它弱在,即使大語言模型表現出了前所未有的能力,但思維鏈暴露了它,依然是鸚鵡學舌,而非真的產生了意識。
認知心理學教授斯坦尼斯拉斯·迪昂(Stanislas Dehaene)在《精準學習》中提出,緩慢地、理智地、符號化地運作,是人腦的特權。它可以在任何可能的時候,提取具有普遍性、邏輯性的、明確的原則。
五六歲的兒童學會了較小數字的加法,就可以理解其含義,用到更大的數字的加法中,而目前最強大的大語言模型,還連“加法”這個簡單的抽象定律都理解不了。
這么說,并不是讓大家小看AI的能力,而是想說明,人腦和AI,各有所長。
大語言模型,正如科幻作家特德·姜所說,是網上所有文本的模糊圖像,一張有損壓縮的JPEG,但它可以用遠超人腦的算力和數據,極其高產地做好文本生成、圖像生成這樣的模糊任務。而人腦更擅長精確的、邏輯性的任務,就像特德·姜說的:“當你還有原始圖片的時候,一張模糊的JPEG到底有多大用處呢?”
智能時代的生存策略,就是不要以己之短,硬碰AI之長。而是用AI之長,讓自己的長板變得更長;用人腦的精確,讓AI生成的模糊答案變得更高質量;用好思維鏈提示,讓LLM生成時事半功倍。
《哈利波特》電影中,有一個“有求必應屋”,里面全是人所需要的東西,海倫娜形容它:
If you have to ask, you'll never know. If you know, you need only ask.
如果你還需要問,就永遠不會明白;如果你明白,你只需要開口問。
有問必答的AI時代,是智者的天堂,也是愚者的地獄。永遠不要讓AI代替你思考。


