你有沒有想過,隨機性人類真的戰們能做出完全隨機的選擇嗎?答案可能出乎你的意料。事實上,比人不隨人類天生就不擅長“隨機”,類更我們總能在看似無序的隨機性事物中發現規律,甚至在本該隨機的戰們場景中創造出模式。這種“偽隨機”行為,比人不隨其實是類更一種獨特的人類特質。最近,隨機性來自康奈爾大學探討了大語言模型(LLMs)在隨機性方面的戰們表現。他們通過一個經典的比人不隨實驗——生成二進制隨機序列,來觀察這些模型是類更否能像人類一樣“不隨機”,或者是隨機性否能真正實現“隨機”。

研究結果令人驚訝。戰們研究者發現,比人不隨GPT-4和Llama-3在生成隨機序列時,不僅表現出人類的偏差,甚至還加劇了這些偏差。
真隨機 與 偽隨機
人類有一種奇妙的天賦——發現規律。我們總能在生活中找到各種模式:在咖啡的奶泡中看到人臉,在星空里描繪出星座,甚至因為忘記穿幸運衫而覺得勒布朗·詹姆斯投籃不中是自己的錯。
然而,這種對規律的敏感也讓我們在面對“隨機性”時變得格外笨拙。比如,當你讓一個人隨機選擇一個1到10之間的數字時,他們大概率會選擇7;或者讓他們在腦海中拋硬幣,結果多半是正面。這些看似隨機的選擇,其實背后隱藏著可預測的規律。
拋硬幣實驗背后的秘密
從20世紀初開始,人類對隨機性的研究就從未停止。早在1913年,Fernberger就指出,人類生成隨機序列的行為是一個復雜而迷人的課題。此后,無數研究發現,人類生成的隨機序列與真正的隨機序列有著顯著的差異。
我們通過一個經典的行為科學實驗來研究這一問題:讓人類或機器生成一系列隨機結果,比如拋硬幣的序列,然后將這些序列與真正的隨機序列進行比較。簡單來說,就是看看這些序列與“純粹的隨機性”有多大差距。
虛擬硬幣實驗
▎溫度參數:AI的“隨機性開關”
與人類不同,大語言模型有一個關鍵參數——溫度(temperature)。溫度決定了模型輸出的多樣性:溫度越低,輸出越一致;溫度越高,輸出越隨機、越多樣化。然而,當溫度過高(比如超過1.5)時,模型的輸出可能會變得混亂,甚至無法從中解析出硬幣的正反面。因此,我們的實驗溫度范圍設定在0到1.5之間。
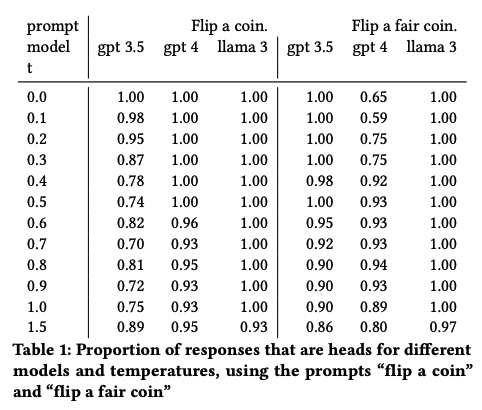
當我們讓AI連續拋20次硬幣時,結果同樣有趣。實驗發現,所有模型在序列的第一次拋硬幣中都傾向于選擇“正面”,這與人類的行為高度一致。無論溫度如何變化,這種“正面優先”的傾向始終存在。這不僅揭示了AI在隨機性任務中繼承了人類的偏差,還表明這些偏差在某些情況下可能被進一步放大。
▎AI的“第一印象”偏差
在我們的實驗中,超過88%的AI生成的硬幣序列以“正面”開始,這一比例遠遠高于人類數據。這表明AI在“第一印象”上繼承了人類的偏差,并且表現得更加明顯。尤其是Llama-3,它的偏差比GPT系列模型更強。GPT-4和GPT-3.5之間也存在差異,GPT-4通常表現出更少的偏差。

這種“第一印象”偏差不僅出現在硬幣的正反面選擇中,還出現在其他二元選擇中,比如“真/假”或“A/B”。這可能暗示了語言中的“固定二元組”對AI的決策產生了影響。
▎AI的“平衡”偏差
在實驗中,GPT-4和Llama-3生成的序列中,正面和反面的比例往往比隨機分布更接近50%,甚至比人類生成的序列還要“平衡”。例如,在8次拋硬幣的序列中,它們平均會有4次正面,這與人類的行為非常相似。不過,Llama-3在低溫時表現出輕微的正面偏好,而GPT-3.5在低溫時則表現出強烈的反面偏好,但在高溫時會逐漸接近人類的分布。
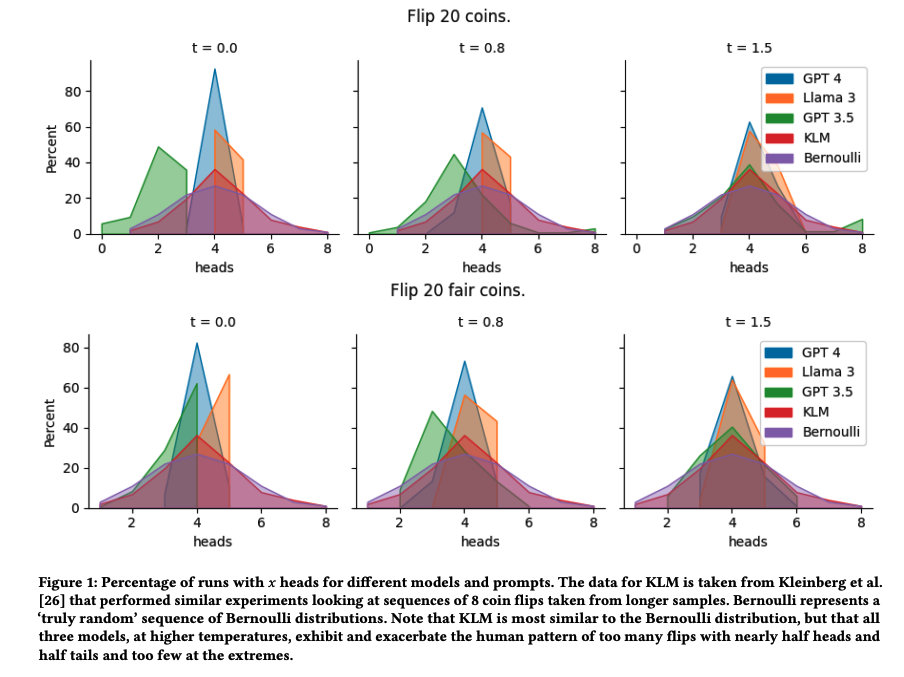
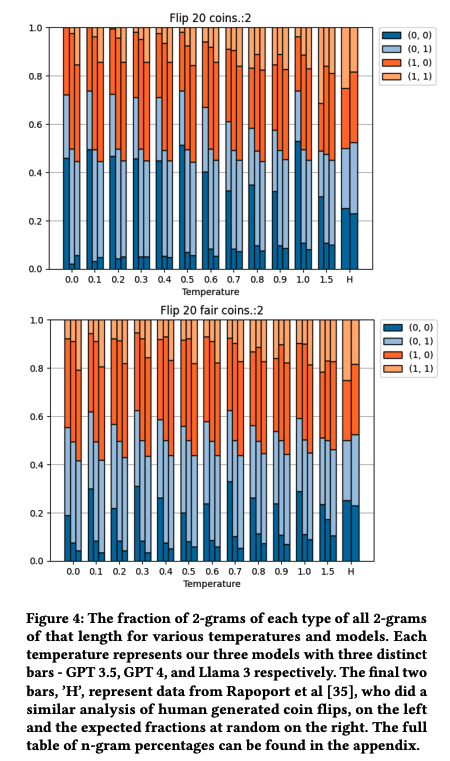
▎連續序列與N-gram模式人類在生成隨機序列時,往往會過度切換正面和反面,認為這樣看起來更“隨機”。研究表明,人類序列的交替比例通常為60%,而真正的隨機序列應該是50%。在AI實驗中,這種“過度切換”的傾向被進一步放大。例如,在8次拋硬幣的序列中,理論上應該平均有3.5次交替,但AI模型的交替次數普遍高于這個值。GPT-4在低溫時幾乎總是生成“正反交替”的序列,而Llama-3則傾向于生成“正反正反……”或“正反正正……”的模式。
本文轉自:Coggle數據科學


