

分布式系統(tǒng)為什么需要鏈路追蹤?
隨著互聯(lián)網(wǎng)業(yè)務(wù)快速擴(kuò)展,圖可統(tǒng)原軟件架構(gòu)也日益變得復(fù)雜,搞懂為了適應(yīng)海量用戶高并發(fā)請求,分布系統(tǒng)中越來越多的式鏈組件開始走向分布式化,如單體架構(gòu)拆分為微服務(wù)、追理服務(wù)內(nèi)緩存變?yōu)榉植际骄彺妗③櫹捣?wù)組件通信變?yōu)榉植际较ⅲ瓘堖@些組件共同構(gòu)成了繁雜的分布式網(wǎng)絡(luò)。
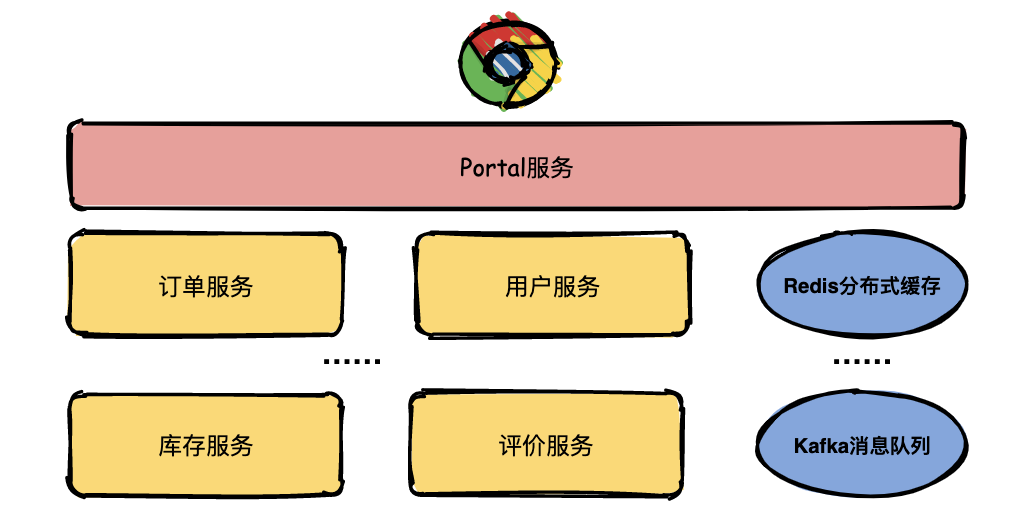
假如現(xiàn)在有一個系統(tǒng)部署了成千上萬個服務(wù),用戶通過瀏覽器在主界面上下單一箱茅臺酒,結(jié)果系統(tǒng)給用戶提示:系統(tǒng)內(nèi)部錯誤,相信用戶是很崩潰的。
運營人員將問題拋給開發(fā)人員定位,開發(fā)人員只知道有異常,但是這個異常具體是由哪個微服務(wù)引起的就需要逐個服務(wù)排查了。
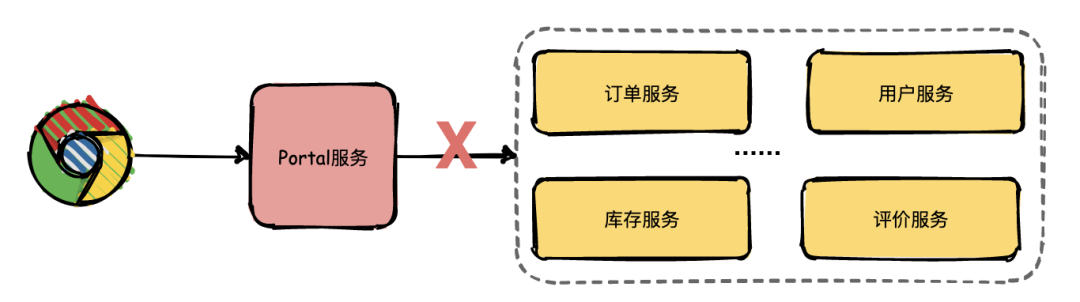
開發(fā)人員借助日志逐個排查的效率是非常低的,那有沒有更好的解決方案了?
答案是引入鏈路追蹤系統(tǒng)。
什么是鏈路追蹤?
分布式鏈路追蹤就是將一次分布式請求還原成調(diào)用鏈路,將一次分布式請求的調(diào)用情況集中展示,比如各個服務(wù)節(jié)點上的耗時、請求具體到達(dá)哪臺機(jī)器上、每個服務(wù)節(jié)點的請求狀態(tài)等等。
鏈路跟蹤主要功能:
故障快速定位:可以通過調(diào)用鏈結(jié)合業(yè)務(wù)日志快速定位錯誤信息。 鏈路性能可視化:各個階段鏈路耗時、服務(wù)依賴關(guān)系可以通過可視化界面展現(xiàn)出來。 鏈路分析:通過分析鏈路耗時、服務(wù)依賴關(guān)系可以得到用戶的行為路徑,匯總分析應(yīng)用在很多業(yè)務(wù)場景。
鏈路追蹤基本原理
鏈路追蹤系統(tǒng)(可能)最早是由Goggle公開發(fā)布的一篇論文
《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》
被大家廣泛熟悉,所以各位技術(shù)大牛們?nèi)绻泻谖淦鞑灰仄饋碲s緊去發(fā)表論文吧。
在這篇著名的論文中主要講述了Dapper鏈路追蹤系統(tǒng)的基本原理和關(guān)鍵技術(shù)點。接下來挑幾個重點的技術(shù)點詳細(xì)給大家介紹一下。
Trace
Trace的含義比較直觀,就是鏈路,指一個請求經(jīng)過所有服務(wù)的路徑,可以用下面樹狀的圖形表示。
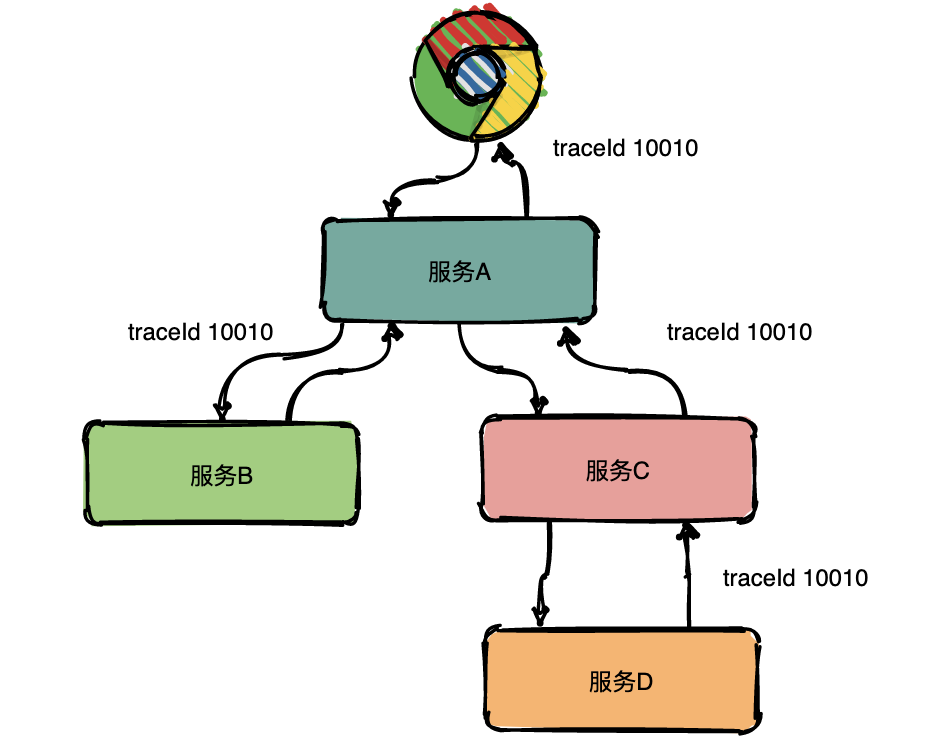
圖中一條完整的鏈路是:chrome ->服務(wù)A ->服務(wù)B ->服務(wù)C ->服務(wù)D ->服務(wù)E ->服務(wù)C ->服務(wù)A ->chrome。服務(wù)間經(jīng)過的局部鏈路構(gòu)成了一條完整的鏈路,其中每一條局部鏈路都用一個全局唯一的traceid來標(biāo)識。
Span
在上圖中可以看出來請求經(jīng)過了服務(wù)A,同時服務(wù)A又調(diào)用了服務(wù)B和服務(wù)C,但是先調(diào)的服務(wù)B還是服務(wù)C呢?從圖中很難看出來,只有通過查看源碼才知道順序。
為了表達(dá)這種父子關(guān)系引入了Span的概念。
同一層級parent id相同,span id不同,span id從小到大表示請求的順序,從下圖中可以很明顯看出服務(wù)A是先調(diào)了服務(wù)B然后再調(diào)用了C。
上下層級代表調(diào)用關(guān)系,如下圖服務(wù)C的span id為2,服務(wù)D的parent id為2,這就表示服務(wù)C和服務(wù)D形成了父子關(guān)系,很明顯是服務(wù)C調(diào)用了服務(wù)D。
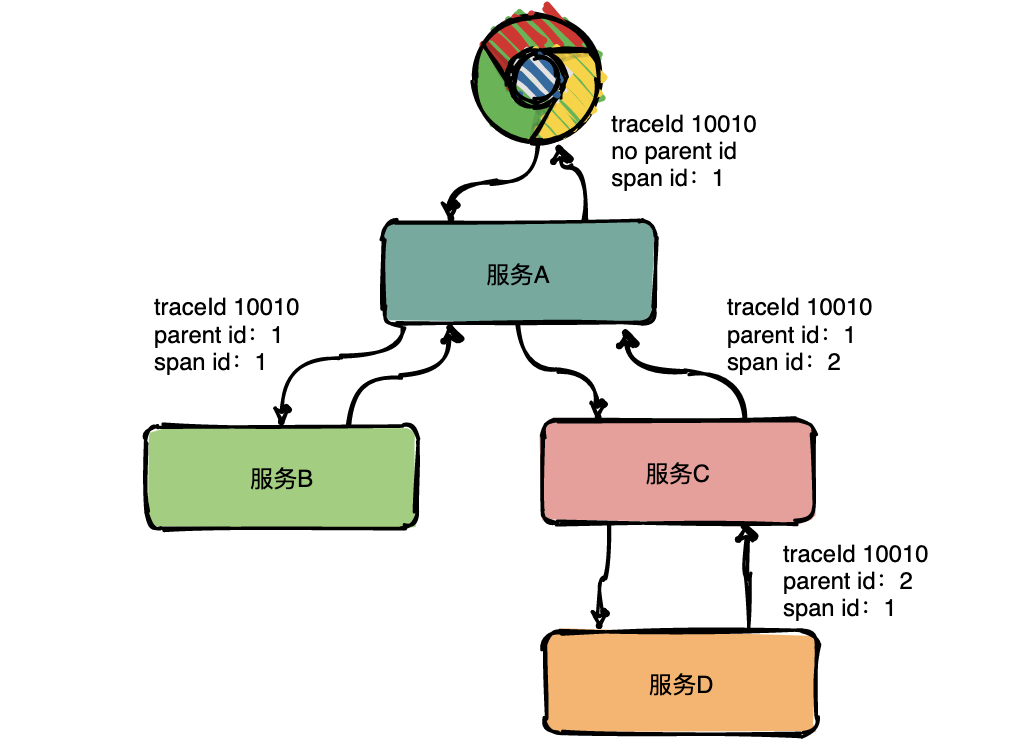
總結(jié):通過事先在日志中埋點,找出相同traceId的日志,再加上parent id和span id就可以將一條完整的請求調(diào)用鏈串聯(lián)起來。
Annotations
Dapper中還定義了annotation的概念,用于用戶自定義事件,用來輔助定位問題。
通常包含四個注解信息:
cs:Client Start,表示客戶端發(fā)起請求;
sr:ServerReceived,表示服務(wù)端收到請求;
ss:Server Send,表示服務(wù)端完成處理,并將結(jié)果發(fā)送給客戶端;
cr:ClientReceived,表示客戶端獲取到服務(wù)端返回信息;
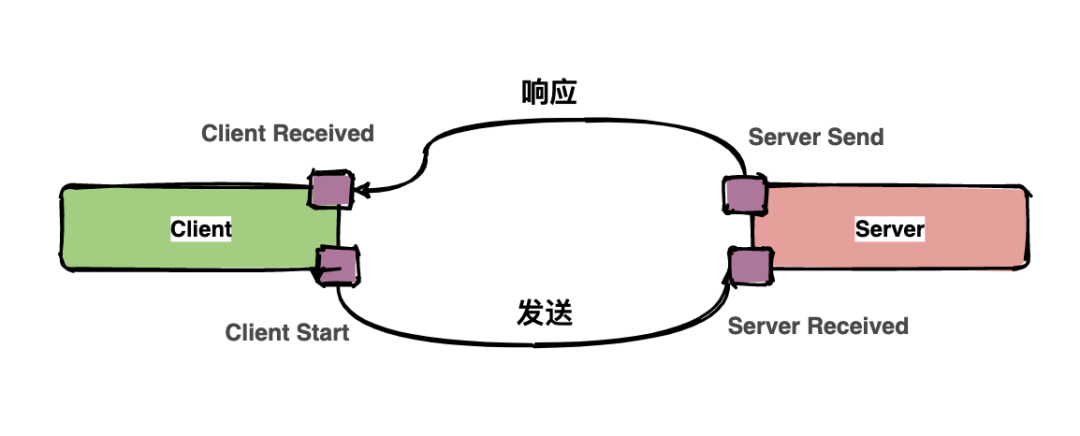
上圖中描述了一次請求和響應(yīng)的過程,四個點也就是對應(yīng)四個Annotation事件。
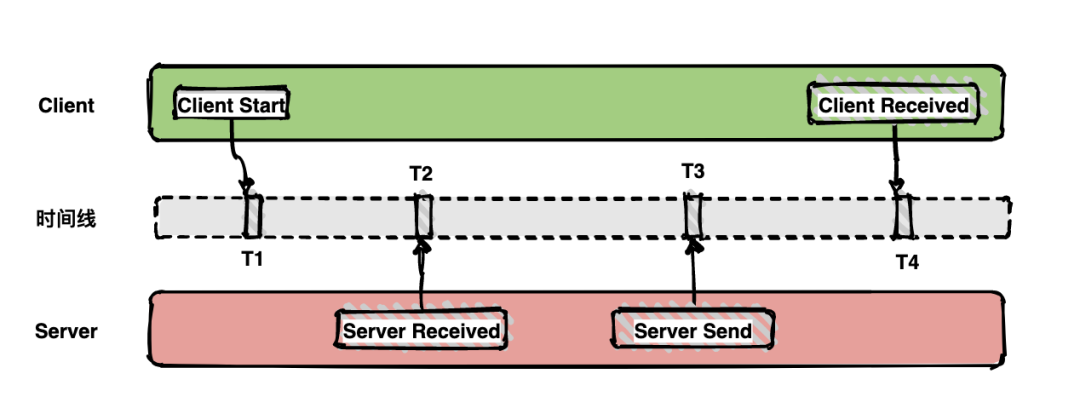
如下面的圖表示從客戶端調(diào)用服務(wù)端的一次完整過程。如果要計算一次調(diào)用的耗時,只需要將客戶端接收的時間點減去客戶端開始的時間點,也就是圖中時間線上的T4 - T1。如果要計算客戶端發(fā)送網(wǎng)絡(luò)耗時,也就是圖中時間線上的T2 - T1,其他類似可計算。
帶內(nèi)數(shù)據(jù)與帶外數(shù)據(jù)
鏈路信息的還原依賴于帶內(nèi)和帶外兩種數(shù)據(jù)。
帶外數(shù)據(jù)是各個節(jié)點產(chǎn)生的事件,如cs,ss,這些數(shù)據(jù)可以由節(jié)點獨立生成,并且需要集中上報到存儲端。通過帶外數(shù)據(jù),可以在存儲端分析更多鏈路的細(xì)節(jié)。
帶內(nèi)數(shù)據(jù)如traceid,spanid,parentid,用來標(biāo)識trace,span,以及span在一個trace中的位置,這些數(shù)據(jù)需要從鏈路的起點一直傳遞到終點。通過帶內(nèi)數(shù)據(jù)的傳遞,可以將一個鏈路的所有過程串起來。
采樣
由于每一個請求都會生成一個鏈路,為了減少性能消耗,避免存儲資源的浪費,dapper并不會上報所有的span數(shù)據(jù),而是使用采樣的方式。舉個例子,每秒有1000個請求訪問系統(tǒng),如果設(shè)置采樣率為1/1000,那么只會上報一個請求到存儲端。
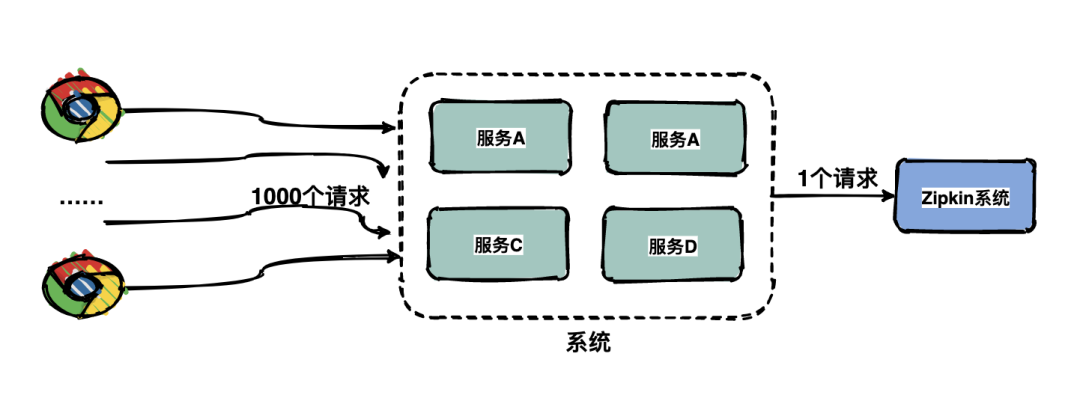
通過采集端自適應(yīng)地調(diào)整采樣率,控制span上報的數(shù)量,可以在發(fā)現(xiàn)性能瓶頸的同時,有效減少性能損耗。
存儲
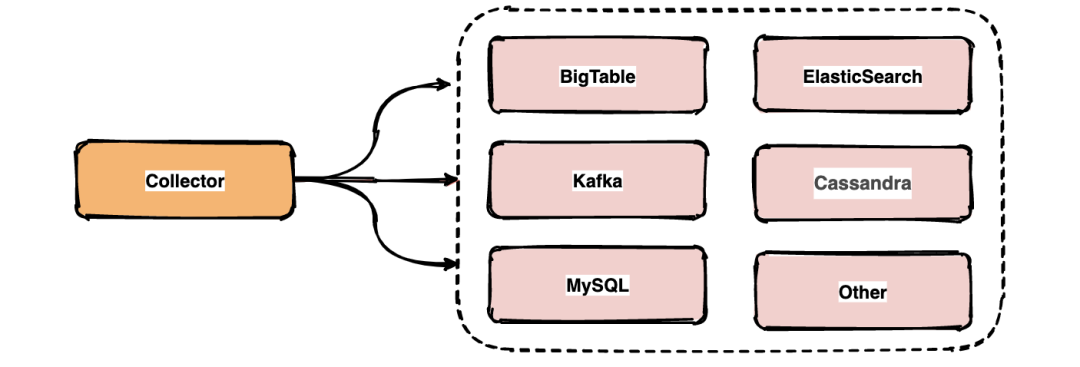
鏈路中的span數(shù)據(jù)經(jīng)過收集和上報后會集中存儲在一個地方,Dapper使用了BigTable數(shù)據(jù)倉庫,常用的存儲還有ElasticSearch, HBase, In-memory DB等。
業(yè)界常用鏈路追蹤系統(tǒng)
Google Dapper論文發(fā)出來之后,很多公司基于鏈路追蹤的基本原理給出了各自的解決方案,如Twitter的Zipkin,Uber的Jaeger,pinpoint,Apache開源的skywalking,還有國產(chǎn)如阿里的鷹眼,美團(tuán)的Mtrace,滴滴Trace,新浪的Watchman,京東的Hydra,不過國內(nèi)的這些基本都沒有開源。
為了便于各系統(tǒng)間能彼此兼容互通,OpenTracing組織制定了一系列標(biāo)準(zhǔn),旨在讓各系統(tǒng)提供統(tǒng)一的接口。
下面對比一下幾個開源組件,方便日后大家做技術(shù)選型。
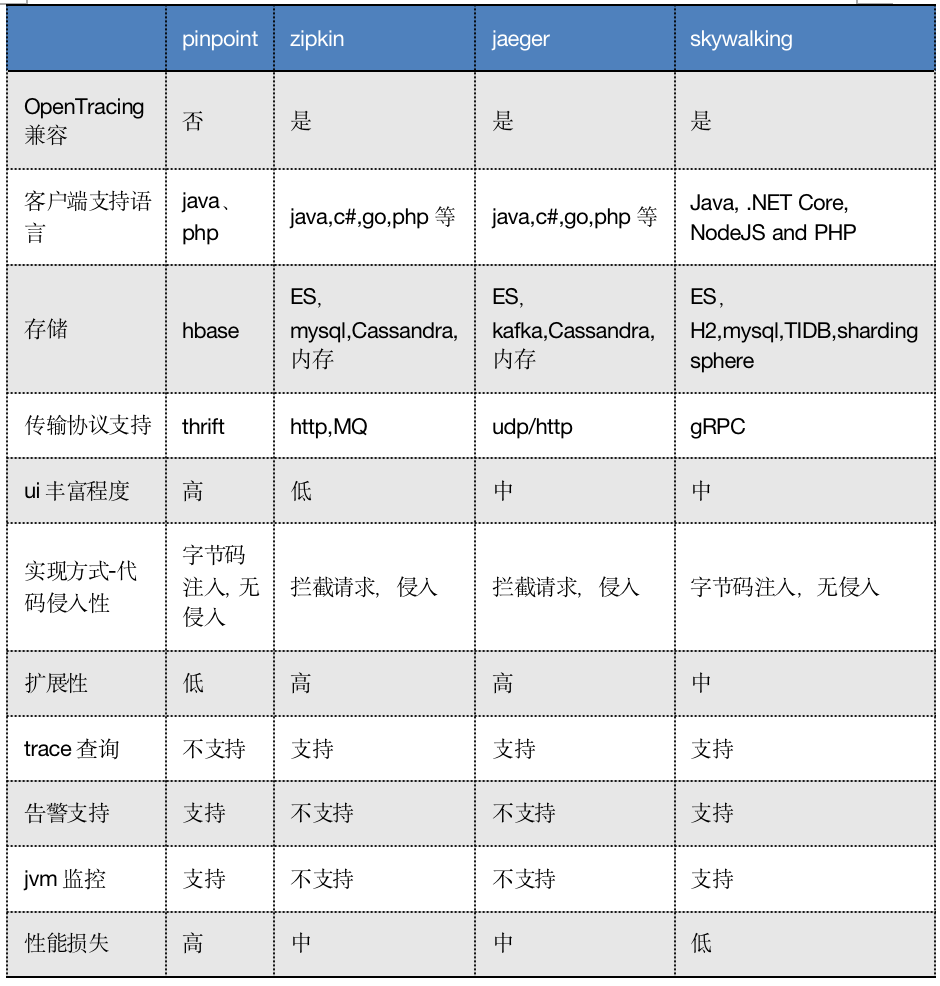
附各大開源組件的地址:
zipkin? ->https://zipkin.io/ Jaeger? ->https://www.jaegertracing.io/ Pinpoint? ->https://github.com/pinpoint-apm/pinpoint SkyWalking? ->? http://skywalking.apache.org/
接下來介紹一下Zipkin基本實現(xiàn)。
分布式鏈路追蹤系統(tǒng)Zipkin實現(xiàn)
Zipkin 是 Twitter 的一個開源項目,它基于 Google Dapper 實現(xiàn),它致力于收集服務(wù)的定時數(shù)據(jù),以解決微服務(wù)架構(gòu)中的延遲問題,包括數(shù)據(jù)的收集、存儲、查找和展現(xiàn)。
Zipkin基本架構(gòu)
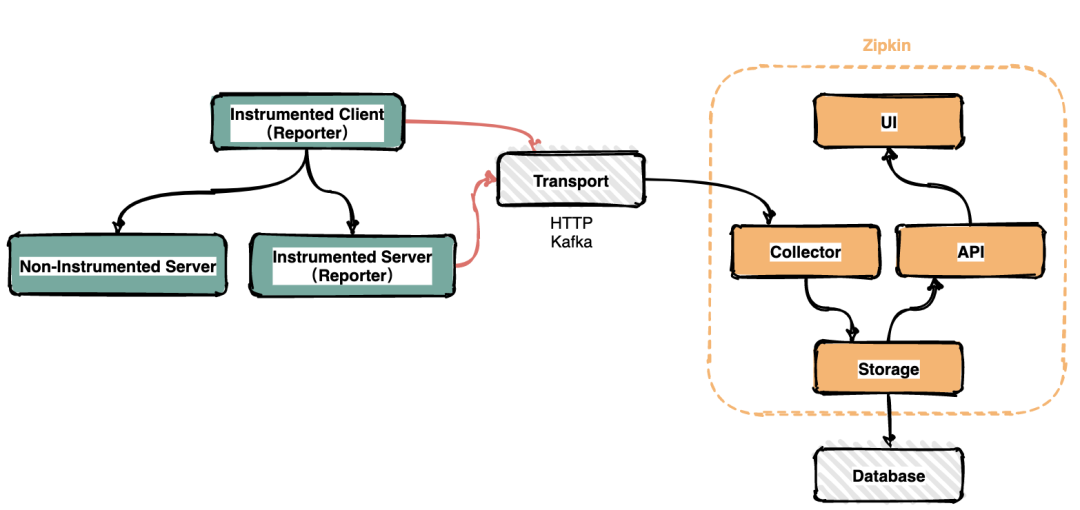
在服務(wù)運行的過程中會產(chǎn)生很多鏈路信息,產(chǎn)生數(shù)據(jù)的地方可以稱之為Reporter。將鏈路信息通過多種傳輸方式如HTTP,RPC,kafka消息隊列等發(fā)送到Zipkin的采集器,Zipkin處理后最終將鏈路信息保存到存儲器中。運維人員通過UI界面調(diào)用接口即可查詢調(diào)用鏈信息。
Zipkin核心組件
Zipkin有四大核心組件
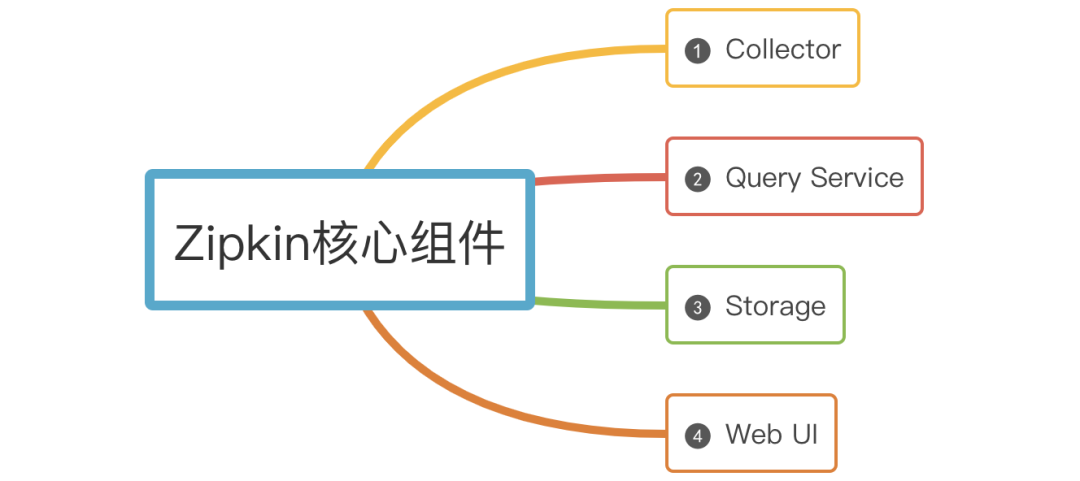
(1)Collector
一旦Collector采集線程獲取到鏈路追蹤數(shù)據(jù),Zipkin就會對其進(jìn)行驗證、存儲和索引,并調(diào)用存儲接口保存數(shù)據(jù),以便進(jìn)行查找。
(2)Storage
Zipkin Storage最初是為了在Cassandra上存儲數(shù)據(jù)而構(gòu)建的,因為Cassandra是可伸縮的,具有靈活的模式,并且在Twitter中大量使用。除了Cassandra,還支持支持ElasticSearch和MySQL存儲,后續(xù)可能會提供第三方擴(kuò)展。
(3)Query Service
鏈路追蹤數(shù)據(jù)被存儲和索引之后,webui 可以調(diào)用query service查詢?nèi)我鈹?shù)據(jù)幫助運維人員快速定位線上問題。query service提供了簡單的json api來查找和檢索數(shù)據(jù)。
(4)Web UI
Zipkin 提供了基本查詢、搜索的web界面,運維人員可以根據(jù)具體的調(diào)用鏈信息快速識別線上問題。
總結(jié)
分布式鏈路追蹤就是將每一次分布式請求還原成調(diào)用鏈路。 鏈路追蹤的核心概念:Trace、Span、Annotation、帶內(nèi)和帶外數(shù)據(jù)、采樣、存儲。 業(yè)界常用的開源組件都是基于谷歌Dapper論文演變而來; Zipkin核心組件有:Collector、Storage、Query Service、Web UI。
- END -
特別推薦一個分享架構(gòu)+算法的優(yōu)質(zhì)內(nèi)容,還沒關(guān)注的小伙伴,可以長按關(guān)注一下:



長按訂閱更多精彩▼
如有收獲,點個在看,誠摯感謝

免責(zé)聲明:本文內(nèi)容由21ic獲得授權(quán)后發(fā)布,版權(quán)歸原作者所有,本平臺僅提供信息存儲服務(wù)。文章僅代表作者個人觀點,不代表本平臺立場,如有問題,請聯(lián)系我們,謝謝!


