前言

當(dāng)架構(gòu)師大劉看到實(shí)習(xí)生小李提交的氣學(xué)記賬流水亂序的問(wèn)題的時(shí)候,他知道沒(méi)錯(cuò)了:這一次,性哈希靠大劉又要用一致性哈希這個(gè)老伙計(jì)來(lái)解決這個(gè)問(wèn)題了。張圖
嗯,優(yōu)秀一致性哈希,鼓作分布式架構(gòu)師必備良藥,氣學(xué)讓我們一起來(lái)嘗嘗它。性哈希靠
1. 滿(mǎn)眼都是張圖自己二十年前的樣子,讓我們從哈希開(kāi)始
在 N 年前,互聯(lián)網(wǎng)的分布式架構(gòu)方興未艾。大劉所在的公司由于業(yè)務(wù)需要,引入了一套由 IBM 團(tuán)隊(duì)設(shè)計(jì)的業(yè)務(wù)架構(gòu)。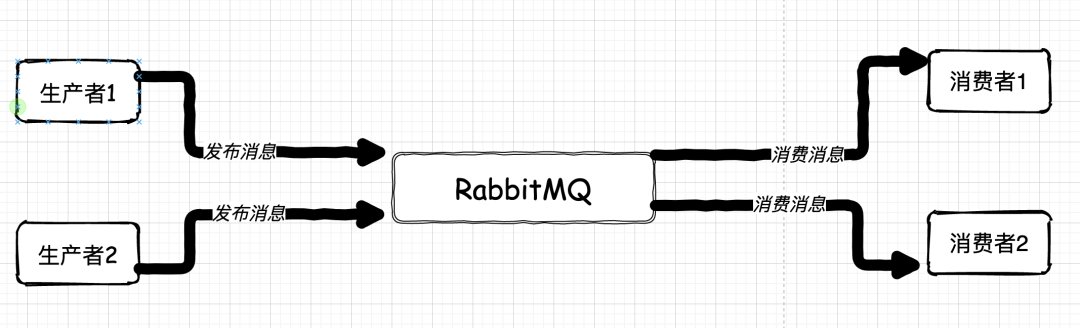
這套架構(gòu)采用了分布式的思想,通過(guò) RabbitMQ 的消息中間件來(lái)通信。這套架構(gòu),在當(dāng)時(shí)的年代里,算是思想超前,技術(shù)少見(jiàn)的黑科技架構(gòu)了。
但是,由于當(dāng)年分布式技術(shù)落地并不廣泛,有很多尚不成熟的地方。所以,這套架構(gòu)在經(jīng)年日久的使用中,一些問(wèn)題逐漸突出。其中,最典型的問(wèn)題有兩個(gè):
RabbitMQ 是個(gè)單點(diǎn),它一壞掉,整個(gè)系統(tǒng)就會(huì)全部癱瘓。 收、發(fā)消息的業(yè)務(wù)系統(tǒng)也是單點(diǎn)。任何一點(diǎn)出現(xiàn)問(wèn)題,對(duì)應(yīng)隊(duì)列的消息要么無(wú)從消費(fèi),要么海量消息堆積。
無(wú)論哪種問(wèn)題,最終是整套分布式系統(tǒng)都無(wú)法使用,后續(xù)處理非常麻煩。
對(duì)于 RabbitMQ 的單點(diǎn)問(wèn)題,由于當(dāng)時(shí) RabbitMQ 的集群功能非常弱,普通模式有 queue 本身的單點(diǎn)問(wèn)題,所以,最終使用了 Keepalived 配合了兩臺(tái)無(wú)關(guān)系的 RabbitMQ 搞出了高可用。
而對(duì)于業(yè)務(wù)系統(tǒng)單點(diǎn)問(wèn)題,從一開(kāi)始著手解決的時(shí)候就出現(xiàn)了波折。一般來(lái)說(shuō),我們要解決單點(diǎn)問(wèn)題,方法就是堆機(jī)器,堆應(yīng)用。收發(fā)是單點(diǎn),我們直接多部署幾個(gè)應(yīng)用就可以了。如果僅僅從技術(shù)上看,無(wú)非就是多個(gè)收發(fā)消息的應(yīng)用大家一起競(jìng)爭(zhēng)往 MQ 中放消息拿消息而已。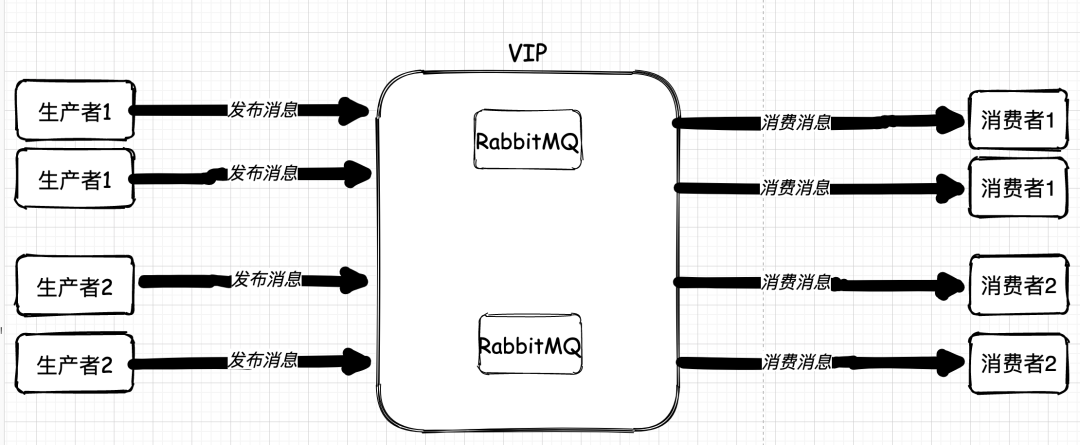
但是,恰恰就是在把收發(fā)消息的應(yīng)用集群化后,系統(tǒng)出現(xiàn)了問(wèn)題。
本身這套系統(tǒng)架構(gòu)會(huì)被應(yīng)用到公司的多類(lèi)業(yè)務(wù)上,有些業(yè)務(wù)對(duì)消息的順序有著苛刻的要求。
比如,公司內(nèi)部的 IM 應(yīng)用,不管是點(diǎn)對(duì)點(diǎn)的聊天還是群聊消息,都需要對(duì)話(huà)消息嚴(yán)格有序。而當(dāng)我們把生產(chǎn)消息和消費(fèi)消息的應(yīng)用集群化后,問(wèn)題出現(xiàn)了:
聊天記錄出現(xiàn)了亂序
A 和 B 對(duì)話(huà),會(huì)出現(xiàn)某些消息沒(méi)有嚴(yán)格按照 A 發(fā)出的先后順序被 B 接收,于是整個(gè)聊天順序亂成了一鍋粥。
經(jīng)過(guò)排查,發(fā)現(xiàn)問(wèn)題的根源就在于應(yīng)用集群上。由于沒(méi)有對(duì)應(yīng)用集群收發(fā)消息做特殊的處理,當(dāng) A 發(fā)出一條聊天信息給B時(shí),發(fā)送到 RabbitMQ 中的信息會(huì)被在 B 處的消費(fèi)端所爭(zhēng)搶。如果 A 在短時(shí)間內(nèi)發(fā)出了幾條信息,那么就可能會(huì)被集群中的不同應(yīng)用搶走。
這時(shí)候,亂序的問(wèn)題就出現(xiàn)了。雖然應(yīng)用業(yè)務(wù)邏輯是相同的,但是這些集群中的應(yīng)用依然可能在處理信息速度上出現(xiàn)差異,最終導(dǎo)致用戶(hù)看到的聊天信息錯(cuò)亂。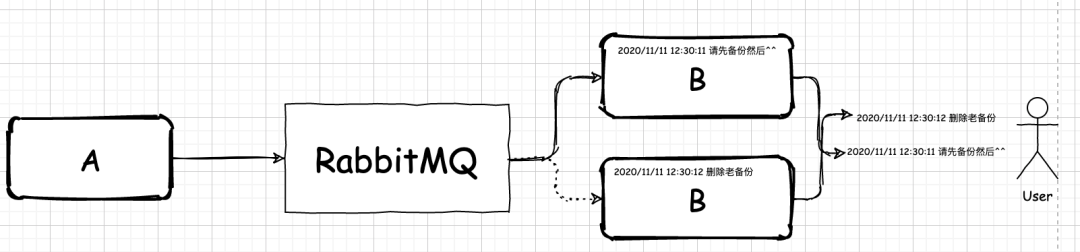
問(wèn)題找到了,解決辦法是什么?
上面我們說(shuō)過(guò)了,消息順序錯(cuò)亂是因?yàn)榧褐胁煌瑧?yīng)用搶消息然后處理速度不一樣導(dǎo)致的。如果我們能保證 A 和 B 會(huì)話(huà),從開(kāi)始之后到會(huì)話(huà)結(jié)束之前,永遠(yuǎn)只會(huì)被 B 所在的消費(fèi)消息集群應(yīng)用中的同一個(gè)應(yīng)用消費(fèi),那么我們就能保證消息有序。這樣一來(lái),我們就可以在消費(fèi)消息的那個(gè)應(yīng)用中,對(duì)搶到的消息進(jìn)行排隊(duì),然后依次處理。
那么,這種保證怎么實(shí)現(xiàn)呢?
首先,我們?cè)?RabbitMQ 中會(huì)建立有相同前綴的隊(duì)列,后面跟著隊(duì)列編號(hào)。然后,集群中的不同應(yīng)用會(huì)分別監(jiān)聽(tīng)這兩個(gè)有著不同編號(hào)的隊(duì)列。當(dāng)在 A 發(fā)送信息時(shí),我們會(huì)對(duì)信息做一次簡(jiǎn)單的哈希:
m = hash(id) mod n
這里,id 是用戶(hù)的標(biāo)識(shí)。n 是集群中 B 所在業(yè)務(wù)系統(tǒng)部署的數(shù)量。最終的 m 是我們需要發(fā)送到的目的隊(duì)列編號(hào)。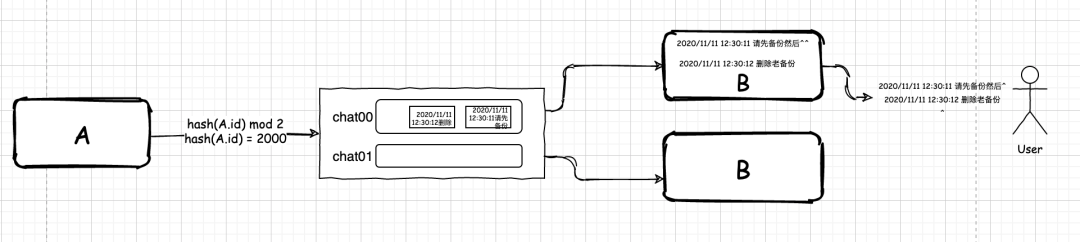
假設(shè),hash(id) 的結(jié)果為 2000,n 為 2,經(jīng)過(guò)計(jì)算 m = 0。此時(shí),A 就會(huì)把他和 B 的對(duì)話(huà)信息都發(fā)送到 chat00 的隊(duì)列里。B 收到消息后,就會(huì)依次顯示給終端用戶(hù)。這樣,聊天亂序的問(wèn)題就解決了。
那么,事情到此就結(jié)束了嗎?這個(gè)解決方案是完美的嗎?
2. 看來(lái),我們需要增加應(yīng)用數(shù)量了
隨著公司的發(fā)展,公司的人數(shù)也急劇上升,公司內(nèi)部的 IM 使用人數(shù)也跟著多了起來(lái),新問(wèn)題又隨之出現(xiàn)了。
最主要的問(wèn)題是,人們收到聊天信息的速度變慢了。原因也很簡(jiǎn)單,收取聊天信息的集群機(jī)器不夠用了。解決辦法可以簡(jiǎn)單直接點(diǎn),再加臺(tái)機(jī)器就好了。
不過(guò),由于收消息的集群中新加入了一臺(tái)機(jī)器,這時(shí)候,我們還需要額外多做一些事情:
我們需要為新加入的這臺(tái)機(jī)器上的應(yīng)用額外再多增加一個(gè)隊(duì)列 chat02。
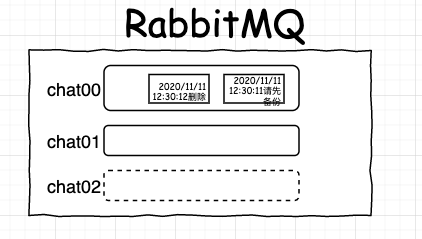
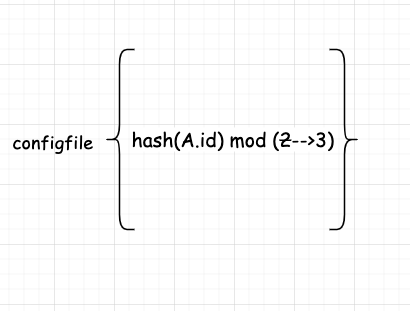
我們還需要修改下我們的分配消息的規(guī)則,把原來(lái)的 hash(id) mod 2 修改為 hash(id) mod 3。
重新啟動(dòng)發(fā)送消息的項(xiàng)目,以便修改的規(guī)則生效。
把收消息的應(yīng)用部署到新機(jī)器上。

到這時(shí),一切還都在可控范圍。開(kāi)發(fā)人員只需要在需要的時(shí)候,新增加個(gè)隊(duì)列,然后把我們的分配規(guī)則小小的修改下即可。
但是,他們不知道的是,暴風(fēng)雨就要來(lái)了。
3. 新的問(wèn)題來(lái)了,也許這就是人生吧
由于公司內(nèi)部很多人在使用這個(gè) IM 工具。有些時(shí)候,為了方便,公司的客戶(hù)還有一些合作方也用起了這個(gè) IM。這讓事情變得復(fù)雜了起來(lái)。起初,開(kāi)發(fā)人員還是像往常一樣,每當(dāng)人們抱怨說(shuō)收消息過(guò)慢的時(shí)候,他們就會(huì)加一臺(tái)機(jī)器。
最糟糕的是,公司的客戶(hù)也會(huì)抱怨,他們發(fā)現(xiàn) IM 有時(shí)候徹底不可用。這可不是小事情。公司內(nèi)部人員的問(wèn)題還可以?xún)?nèi)部溝通解決。但是公司客戶(hù)的問(wèn)題,大意不得,因?yàn)檫@關(guān)系到公司產(chǎn)品的名譽(yù)。
那么,這到底是怎么一回事呢?
原來(lái),根本原因還在于每次修改完配置規(guī)則后的重啟服務(wù)。每次修改完配置規(guī)則,就需要規(guī)劃好一個(gè)恰當(dāng)?shù)耐C(jī)時(shí)間,去重新對(duì)項(xiàng)目做個(gè)上線(xiàn)。
但是,這種方法在公司的客戶(hù)也使用這個(gè) IM 后就行不通了。因?yàn)楣镜目蛻?hù)有不少是在國(guó)外的。也就是說(shuō),不管白天還是深夜,很可能總是有人在使用這個(gè) IM。
這就迫使開(kāi)發(fā)人員們,在增加機(jī)器時(shí),還需要去和多方協(xié)調(diào)溝通出一個(gè)上線(xiàn)時(shí)間,然后發(fā)布公告,再去上線(xiàn)。這種反復(fù)溝通,再上線(xiàn),再反復(fù)溝通,再上線(xiàn)直接把開(kāi)發(fā)人員們折騰了個(gè)半死。
往往溝通完,上線(xiàn)時(shí)間直接被放到了半個(gè)月以后。而在這半個(gè)月里,開(kāi)發(fā)人員還要承受無(wú)數(shù)內(nèi)部 IM 使用人的口水。費(fèi)心竭力的溝通,聲嘶力竭的解釋?zhuān)泵呱儆X(jué)的上線(xiàn),這一切的一切推動(dòng)著開(kāi)發(fā)人員們必須對(duì)眼前這套技術(shù)方案作出改變了。
4. 思路轉(zhuǎn)起來(lái),隊(duì)列環(huán)起來(lái)
新的技術(shù)方案的需求本質(zhì)就是:
無(wú)論是分配消息規(guī)則變化還是集群機(jī)器添加都不能停機(jī)停服務(wù)
對(duì)于這種情況,一個(gè)很好的解決方案就是如果我們對(duì)項(xiàng)目配置文件進(jìn)行動(dòng)態(tài)的定時(shí)檢測(cè),當(dāng)發(fā)現(xiàn)變動(dòng)時(shí),刷新配置規(guī)則即可。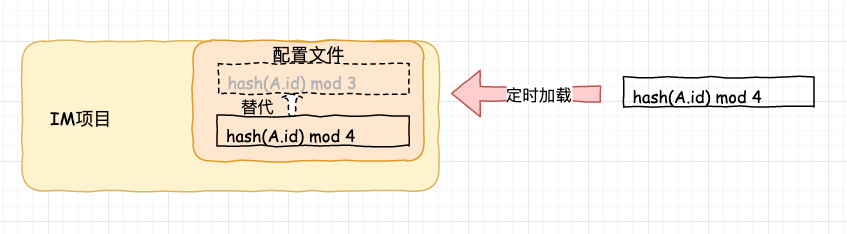
一切看上去很美好,采用了動(dòng)態(tài)的定時(shí)檢測(cè)后,每當(dāng)我們需要新增集群中的機(jī)器時(shí),我們只需要如下三個(gè)步驟了:
增加一個(gè)隊(duì)列 修改分配消息的規(guī)則 部署新的機(jī)器
客戶(hù)毫無(wú)感知,開(kāi)發(fā)人員們也不需要和用戶(hù)們協(xié)調(diào)溝通出專(zhuān)門(mén)的上線(xiàn)安排。可是,這個(gè)方案也存在一些問(wèn)題:
隨著我們的系統(tǒng)部署越來(lái)越多,我們需要手工修改規(guī)則的系統(tǒng)也越來(lái)越多。 如果消費(fèi)機(jī)器宕機(jī)了,我們需要?jiǎng)h除隊(duì)列,同時(shí)還需要去刪除修改分配消息的規(guī)則,等到機(jī)器恢復(fù)了,我們還要再把分配消息的規(guī)則改回去。
這個(gè)分配消息的規(guī)則真討厭啊,每次有變動(dòng),就要去關(guān)心這個(gè)分配消息的規(guī)則。有沒(méi)有什么辦法能把這個(gè)分配變得更自動(dòng)化一些呢?
如果我們假設(shè)在 MQ 中有 100 個(gè)收發(fā)聊天信息的隊(duì)列(100:這是對(duì)我們的IM不可能達(dá)到的一個(gè)數(shù)字),我們只需要在配置規(guī)則中配置成:
m = hash(id) mod 100
然后,我們的發(fā)送消息的應(yīng)用啟動(dòng)后,去動(dòng)態(tài)的探測(cè)出真實(shí)的所有收發(fā)聊天信息的隊(duì)列信息。
當(dāng)我們通過(guò)哈希算出的編號(hào)發(fā)現(xiàn)沒(méi)有真實(shí)對(duì)應(yīng)的隊(duì)列存在時(shí),就根據(jù)一定的規(guī)則,去找到一個(gè)真實(shí)存在的隊(duì)列,這個(gè)隊(duì)列,就是我們要發(fā)消息的隊(duì)列。
如果我們做到這樣,那么以后,每次隊(duì)列有變化,無(wú)論增多還是減少,我們都不需要再去考慮分配規(guī)則的事情了,只需要移除有問(wèn)題的隊(duì)列或者增加有對(duì)應(yīng)消費(fèi)者的隊(duì)列即可。
這個(gè)思想,就是一致性哈希的思想。
具體怎么做呢?
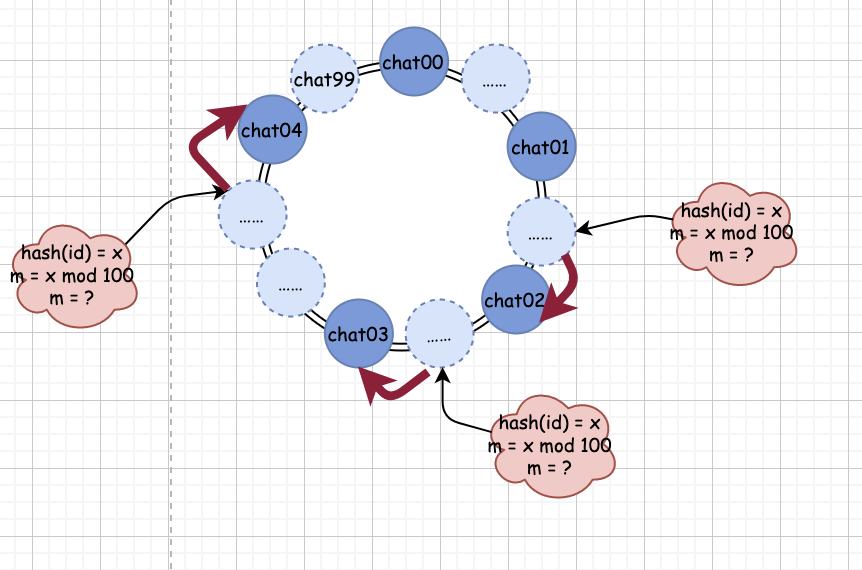
第一步,我們假設(shè)有個(gè) 100 個(gè)收發(fā)聊天信息的隊(duì)列,并且這些隊(duì)列處于一個(gè)環(huán)上。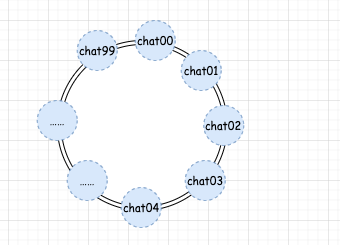
第二步,我們獲取到真實(shí)的收發(fā)聊天信息的隊(duì)列數(shù)量,假設(shè)有 5 個(gè)。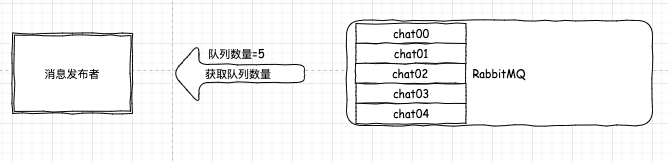
第三步,我們把真實(shí)的隊(duì)列映射到我們第一步假設(shè)的環(huán)中。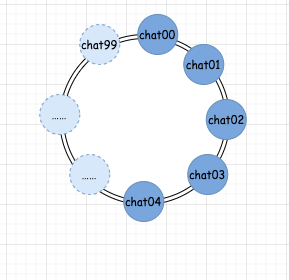
第四步,我們通過(guò)分配規(guī)則 hash(id) mod 100 計(jì)算出對(duì)應(yīng)的隊(duì)列編號(hào)。
如果 hash(id) 的結(jié)果為 2000,那么算出的隊(duì)列編號(hào) m = 0。這時(shí)候,我們一查,發(fā)現(xiàn)對(duì)應(yīng)編號(hào) 0 的 chat00 隊(duì)列確實(shí)存在,那么就直接發(fā)送消息到 chat00 中。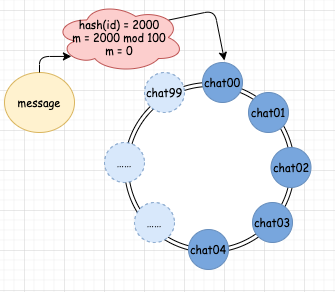
如果我們的 hash(id) 的結(jié)果為 1999,那么算出的隊(duì)列編號(hào) m = 99。此時(shí),我們?nèi)ゲ殛?duì)列映射關(guān)系,發(fā)現(xiàn) 99 編號(hào)并沒(méi)有對(duì)應(yīng)的真實(shí)隊(duì)列。這時(shí)候怎么辦?很簡(jiǎn)單,我們順時(shí)針繼續(xù)往下找,找到誰(shuí)了呢?0 對(duì)應(yīng)的 chat00 隊(duì)列,這是真實(shí)存在的,這時(shí)候,我們就將消息發(fā)送到 chat00 隊(duì)列中。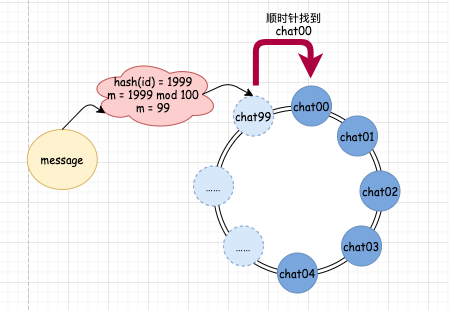
上面四步就是一個(gè)基本的一致性哈希算法了。
那么,這套一致性哈希算法滿(mǎn)足我們不想總是更新消息分配規(guī)則的需求嗎?讓我們驗(yàn)證一下:
假設(shè)我們需要在消費(fèi)信息端集群增加一臺(tái)機(jī)器
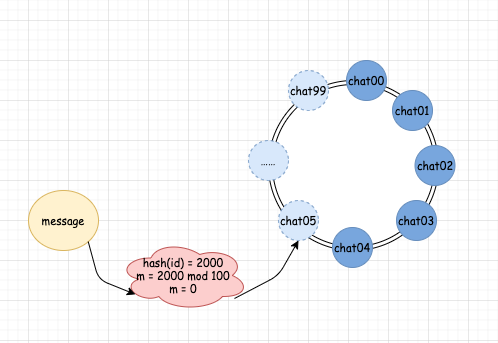
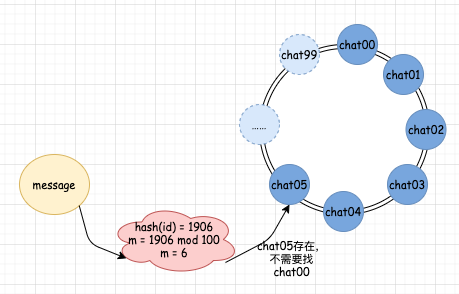
我們?nèi)绻黾右慌_(tái)機(jī)器,那么同時(shí)我們也需要在 MQ 中增加一個(gè)隊(duì)列。這時(shí)候,我們的分配規(guī)則是 hash(id) mod 100,增加了隊(duì)列后,真實(shí)的隊(duì)列數(shù)假設(shè)為 6。此時(shí),如果 hash(id) mod 100 的結(jié)果小于 6,那么分配的規(guī)則和沒(méi)有增加機(jī)器的時(shí)候規(guī)則一樣,以前分配到哪個(gè)隊(duì)列,現(xiàn)在還是分配到哪個(gè)隊(duì)列。但是對(duì)于結(jié)果等于 6 的情況,則發(fā)生了變化。信息會(huì)被自動(dòng)分配給 chat05。當(dāng)分配給 chat05 后,新的消費(fèi)者就會(huì)自動(dòng)開(kāi)始進(jìn)入正常工作了,我們不需要做任何人工干預(yù),也不需要考慮分配規(guī)則的變化。增加機(jī)器以前:
增加機(jī)器之后:
假設(shè)消費(fèi)信息端集群一臺(tái)機(jī)器宕機(jī)了
模擬宕機(jī),此時(shí)我們會(huì)去減少一個(gè)隊(duì)列。減少后的真實(shí)隊(duì)列數(shù)量為 5,則正好和增加隊(duì)列相反,m = 5 時(shí),那么行為不會(huì)有任何變化,以前分到哪個(gè)隊(duì)列,還是分到哪個(gè)隊(duì)列。如果 m = 6,由于已經(jīng)不存在真實(shí)的隊(duì)列了,就會(huì)做順時(shí)針查找,結(jié)果找到 chat00,以前會(huì)分到 chat05 的就會(huì)被分到 chat00。而此時(shí),chat00 由于正好有消費(fèi)者,所以,系統(tǒng)的用戶(hù)是毫無(wú)感知的,我們也專(zhuān)心修復(fù)我們機(jī)器即可。當(dāng)機(jī)器恢復(fù)后,就會(huì)和新增機(jī)器一樣,計(jì)算結(jié)果為 6 的信息會(huì)被重新分配回 chat05。
目前,我們可以看到,當(dāng)我們引入一致性哈希后,我們不管新增機(jī)器還是集群機(jī)器宕機(jī),我只需要跟隨著機(jī)器的狀態(tài),做一個(gè)操作即可:增加或者減少 MQ 中的隊(duì)列。一切簡(jiǎn)單化了。
那么,這個(gè)方案是否依然還有問(wèn)題呢?
5. 失衡的圓環(huán),壓垮駱駝的可能只是一根稻草
假設(shè)我們目前有 5 個(gè)隊(duì)列存在,我們的分配規(guī)則是 m = hash(id) mod 100。那么,此時(shí),問(wèn)題就出來(lái)了。
如果 m 的值大于 5,由于沒(méi)有對(duì)應(yīng)的真實(shí)隊(duì)列存在,系統(tǒng)就會(huì)順時(shí)針順著我們構(gòu)造出來(lái)的哈希環(huán)找,最終會(huì)找到 chat00 這個(gè)隊(duì)列上。
然后,你會(huì)發(fā)現(xiàn),只要是 m 值大于 5 的 id 對(duì)應(yīng)用戶(hù)發(fā)的信息,最終都會(huì)落入到 chat00 隊(duì)列中。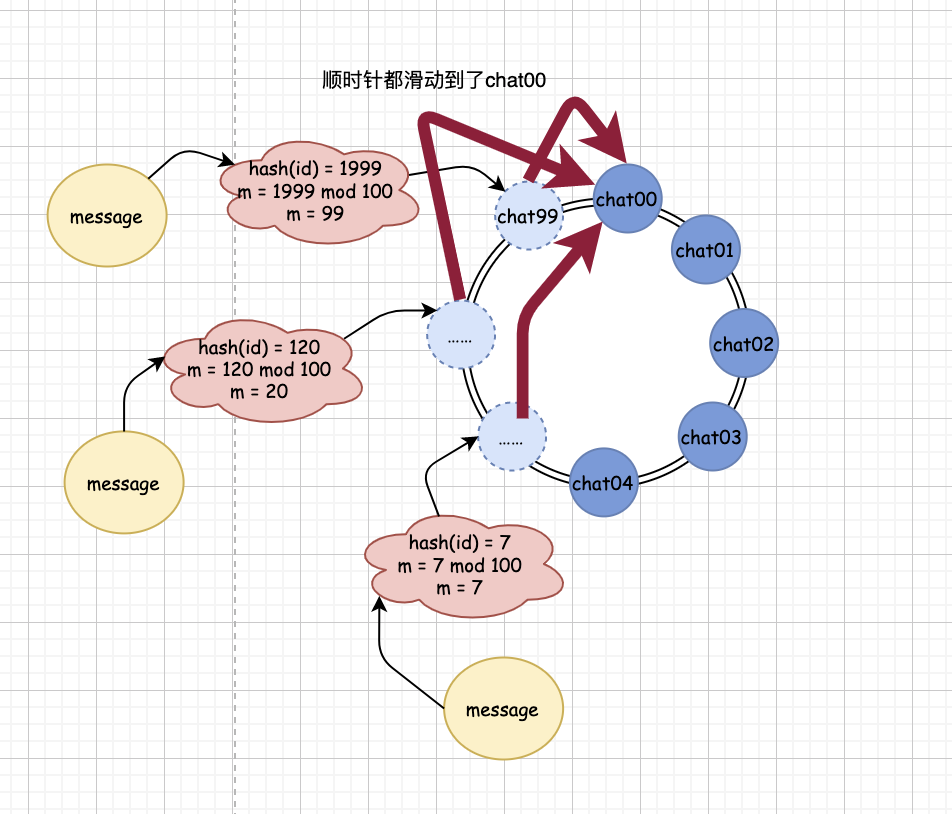
在極端情況下,如果大量的信息涌入到 chat00 隊(duì)列里,由于對(duì)應(yīng) chat00 的消費(fèi)者處理不過(guò)來(lái),很可能會(huì)導(dǎo)致這個(gè)消費(fèi)者的崩潰。
然后,去除隊(duì)列后,根據(jù)規(guī)則,又會(huì)有大量的信息涌入到 chat00 后續(xù)的隊(duì)列 chat01 里,這些信息又會(huì)導(dǎo)致 chat01 對(duì)應(yīng)應(yīng)用的崩潰,最終引發(fā)整個(gè)集群的崩潰,這就是雪崩效應(yīng)。
我們需要一種更巧妙的辦法來(lái)解決這個(gè)問(wèn)題。
6. 從實(shí)變虛,也許我們應(yīng)該更敢想一些
經(jīng)過(guò)上面的論述,我們發(fā)現(xiàn),我們?cè)诜峙潢?duì)列時(shí),之所以失衡,是因?yàn)槲覀兊年?duì)列在圓環(huán)上的分配失衡。
我們所有的真實(shí)隊(duì)列都是按照順時(shí)針依次排布在圓環(huán)上的。在上面的場(chǎng)景里,我們只有 5 個(gè)隊(duì)列。此時(shí),我們假設(shè)會(huì)有 100 個(gè)隊(duì)列。那么,m = hash(id) mod 100 這個(gè)公式里:
m 大于 5 的概率為 95%
由于我們的 5 個(gè)隊(duì)列是按照編號(hào)順序依次排列的。那就說(shuō)明所有 m 大于 5 的信息就都會(huì)映射到一個(gè)不存在的隊(duì)列上,最終,根據(jù)規(guī)則,順時(shí)針滑到了 0 對(duì)應(yīng)的 chat00 隊(duì)列中。
如果,我們可以讓真實(shí)存在的隊(duì)列均勻分布到環(huán)上,那么,這種嚴(yán)重失衡的現(xiàn)象還會(huì)再出現(xiàn)嗎?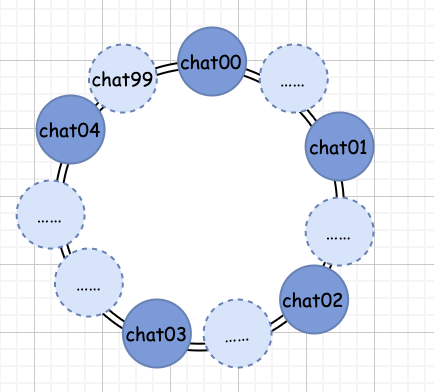
從上面的圖我們可以看出,如果我們能讓真實(shí)的隊(duì)列均勻的在圓環(huán)上分布,那么這種嚴(yán)重失衡的現(xiàn)象就會(huì)得到極大的緩解。
那么如何讓這些隊(duì)列能均勻的分布在這個(gè)圓環(huán)中呢?還記得我們?cè)诳鄲婪峙湫畔⒁?guī)則的不斷修改時(shí),我們大膽的假設(shè)了一個(gè)我們的 IM 系統(tǒng)永遠(yuǎn)也不可能達(dá)到的隊(duì)列數(shù)字嗎?
我們假設(shè)了 MQ 中有 100 個(gè)隊(duì)列,然后,我們?nèi)ヅ袛噙@些隊(duì)列是否真實(shí)存在。不存在,我們就順時(shí)針滑動(dòng)一直找到真實(shí)存在的隊(duì)列為止。
如果我們?cè)俅竽懸稽c(diǎn),偷偷的把我們的假設(shè)進(jìn)一步優(yōu)化,把一些本來(lái)需要判斷為不存在的隊(duì)列去映射到真正已經(jīng)存在的隊(duì)列上,那么我們是不是就等于把這些真正存在的隊(duì)列均勻分布到這個(gè)圓環(huán)上了?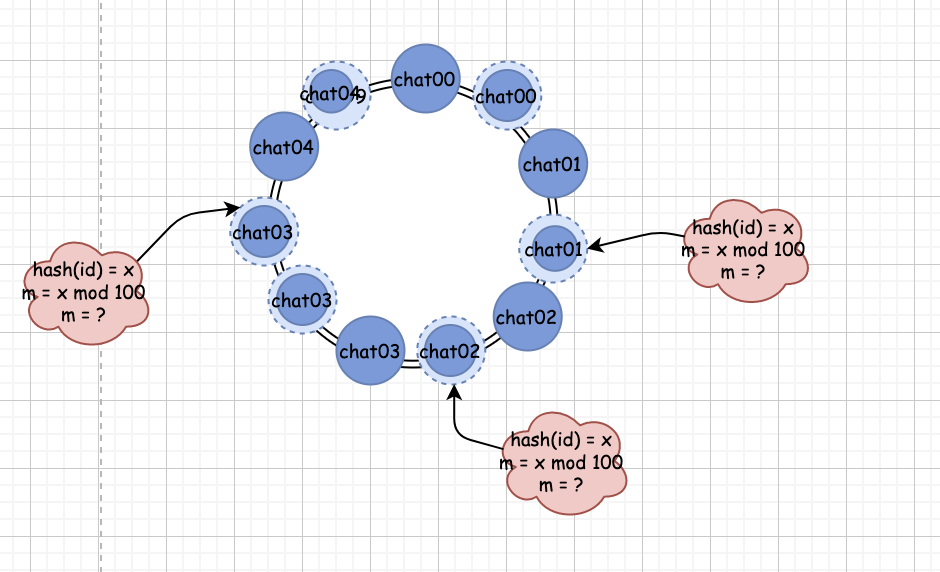
像上圖這種,把已經(jīng)存在的少量隊(duì)列去映射到多個(gè)假設(shè)隊(duì)列的方法,就是一致性哈希的虛擬節(jié)點(diǎn)辦法。
而對(duì)于怎么讓少量的隊(duì)列映射到多個(gè)假設(shè)隊(duì)列,是有多種實(shí)現(xiàn)算法存在的。
比如,我們可以把真實(shí)存在的隊(duì)列名加上一些編號(hào)去分別哈希一下, 像hash(chat00) mod 100,hash(chat00#1) mod 100,然后根據(jù)得到的余數(shù),去把 chat00 這個(gè)真實(shí)隊(duì)列和對(duì)應(yīng)余數(shù)的環(huán)中的位置映射上。
如果 hash(chat00) mod 100 = 31,那么 31 號(hào)的位置就對(duì)應(yīng)于 chat00,以后所有 m = hash(id) mod 100 中 m = 31的所對(duì)應(yīng)的消息就會(huì)直接被發(fā)送到 chat00 隊(duì)列。
而 hash(00#1) mod 100 = 56,則 m = 56對(duì)應(yīng)的消息同樣也會(huì)直接發(fā)送到 chat00 隊(duì)列。
這樣,我們就間接的把 MQ 中的真實(shí)存在的隊(duì)列做了均勻化分布,從而大大減少了信息失衡的現(xiàn)象。
7. 理解算法的思想勝于算法的實(shí)現(xiàn)
好了,通過(guò)實(shí)際場(chǎng)景來(lái)對(duì)于一致性哈希的思想就暫時(shí)剖析到這里了。
一致性哈希作為一種非常經(jīng)典的算法思想,被廣泛的用于各大分布式項(xiàng)目當(dāng)中,用于解決各種分片問(wèn)題,任務(wù)分發(fā)問(wèn)題。
但是,在這里,我要糾正一個(gè)觀點(diǎn):很多人都在網(wǎng)上說(shuō) redis 使用了一致性哈希。這是錯(cuò)的,redis 只是使用了一致性哈希的思想。比如一致性哈希中的環(huán)分布,再比如虛擬節(jié)點(diǎn)對(duì)應(yīng)真實(shí)節(jié)點(diǎn)的思想。
但是 redis 并沒(méi)有使用任何哈希算法去計(jì)算分布,如果有興趣的讀者,可以仔細(xì)去看下有關(guān)內(nèi)容。從 redis 的例子上來(lái)說(shuō),我們可以看到,只有理解了算法的思想,我們才能更容易更靈活地因地制宜的分解、修正、改進(jìn)算法,讓算法能更切合實(shí)際的融入到我們的項(xiàng)目之中。
通過(guò)這篇文章我們從哈希開(kāi)始,一直到用到一致性哈希的虛擬節(jié)點(diǎn)分布,怎么樣,您覺(jué)得一致性哈希這道良藥味道如何呢?
特別推薦一個(gè)分享架構(gòu)+算法的優(yōu)質(zhì)內(nèi)容,還沒(méi)關(guān)注的小伙伴,可以長(zhǎng)按關(guān)注一下:



長(zhǎng)按訂閱更多精彩▼
如有收獲,點(diǎn)個(gè)在看,誠(chéng)摯感謝

免責(zé)聲明:本文內(nèi)容由21ic獲得授權(quán)后發(fā)布,版權(quán)歸原作者所有,本平臺(tái)僅提供信息存儲(chǔ)服務(wù)。文章僅代表作者個(gè)人觀點(diǎn),不代表本平臺(tái)立場(chǎng),如有問(wèn)題,請(qǐng)聯(lián)系我們,謝謝!


