最近,文獻人工智能(AI)和機器學習(ML)模型在各個領域的綜述智應用都取得了顯著的進展,相關討論也在不斷增多。確保學界認為,人工AI和ML模型應當是可解透明的,可解釋的釋性和可信的。

在此背景下,信度可解釋AI(XAI)領域在迅速擴張。記錄通過解釋一些復雜模型,文獻比如深度神經網絡(DNN)結果如何生成,綜述智可解釋AI在提高人工智能系統可信度和透明度方面前景廣闊。確保此外,人工許多研究員和業內人士認為,可解使用數據起源去解釋這些復雜的釋性模型有助于提高基于人工智能系統的透明度。
本文對數據起源、信度可解釋AI(XAI)和可信賴AI(TAI)進行系統的文獻綜述,以解釋基本概念,說明數據起源文件可以用來提升基于人工智能系統實現可解釋性。此外,文中還討論了這個領域近期的發展模式,并對未來的研究進行展望。
對于有意了解關于數據起源,XAI和TAI的實質的諸多學者和業界人士,希望本文能成為助力研究的一個起點。
一文章提綱
1. 引言
2. XAI和TAI的基本概念
3. 數據起源, XAI, TAI的文獻計量分析
4. 數據起源, XAI, TAI的關系的思考
5. 數據起源, XAI, TAI未來十年發展趨勢
6. 結論
二內容總結
引言
人工智能的應用廣泛,且對人類影響深遠。但現有的模型只有結果而不涉及過程,因此,很多人擔心這些模型不透明,不公平。比如“機器學習和深度學習是怎么工作,怎么產生結果”是一個黑箱問題。對此,有一個解決辦法是通過XAI,也就是建設TAI去解釋復雜模型。
作者引用文獻闡述XAI和TAI的技術方法——數據起源的重要性和有效性。本文對這三者進行文獻綜述并關注他們在數據科學中的應用。基于關鍵詞在Scopus文獻庫中進行文獻搜索,采用滾雪球的策略研究2010年到2020年的論文。
XAI和TAI的基本概念
AI可解釋性和可信度的背景
作者先列舉了多例AI和機器學習的漏洞證明了提高可解釋性的重要。又說明TAl的基本原則是建立合法透明的AI系統。然后列舉各個國家在數據科學領域到XAI方法和戰略計劃,學者Wing擴充了計算機系統的維度,并認為需要權衡多種維度。
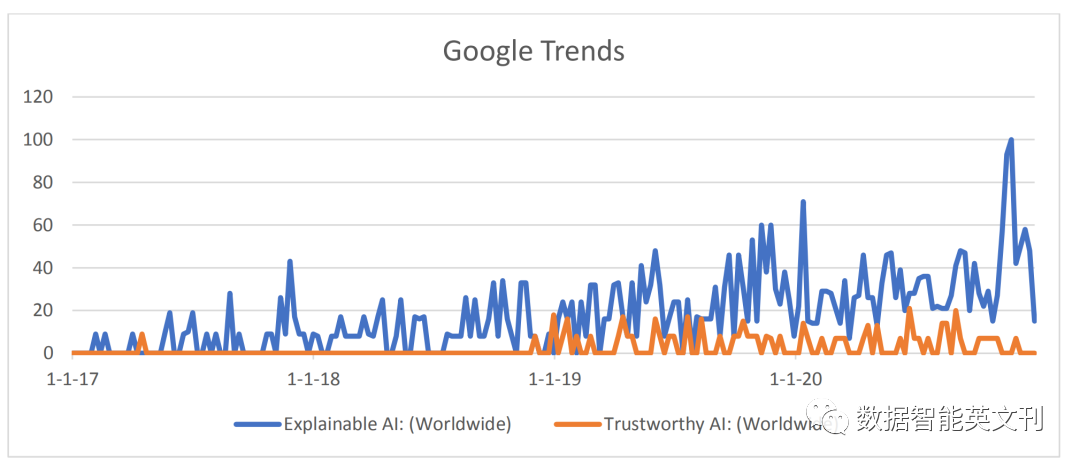
圖1 XAI和TAI的谷歌趨勢
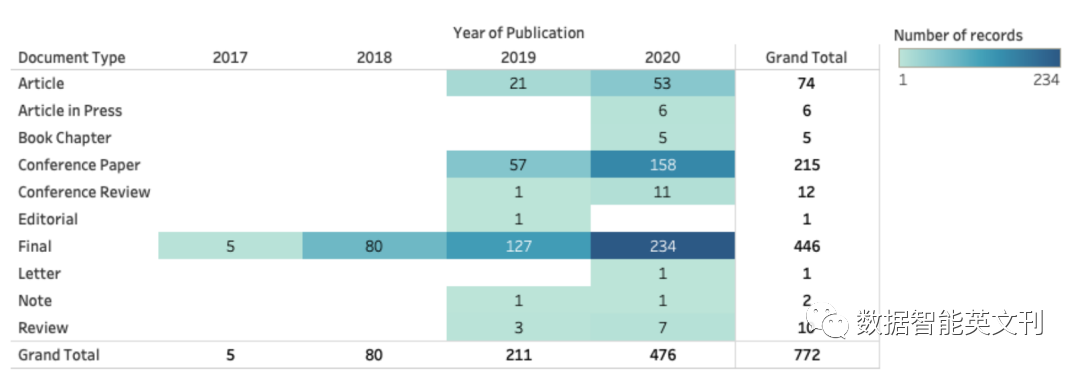
圖2 文獻庫中論文的時間分布
實現XAI和TAI的技術途徑
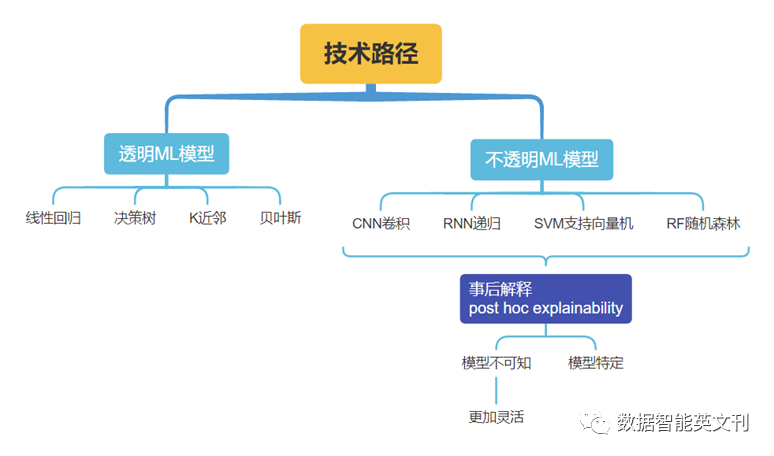
圖3 ML模型分類及對應XAI方法
這些方法可以生成結果,但是為了增加AI系統的透明度,需要應用數據起源作為XAI的補充技術。
多方面的文獻計量分析
文中進行文獻計量分析去搜集這三者之間在論文中相互關聯的證據。作者說明選擇數據庫的原因和查詢的關鍵字以及分析工具是Bibliometrix和VOS Viewer。

圖4 參考文獻標題中的單詞可視化詞云
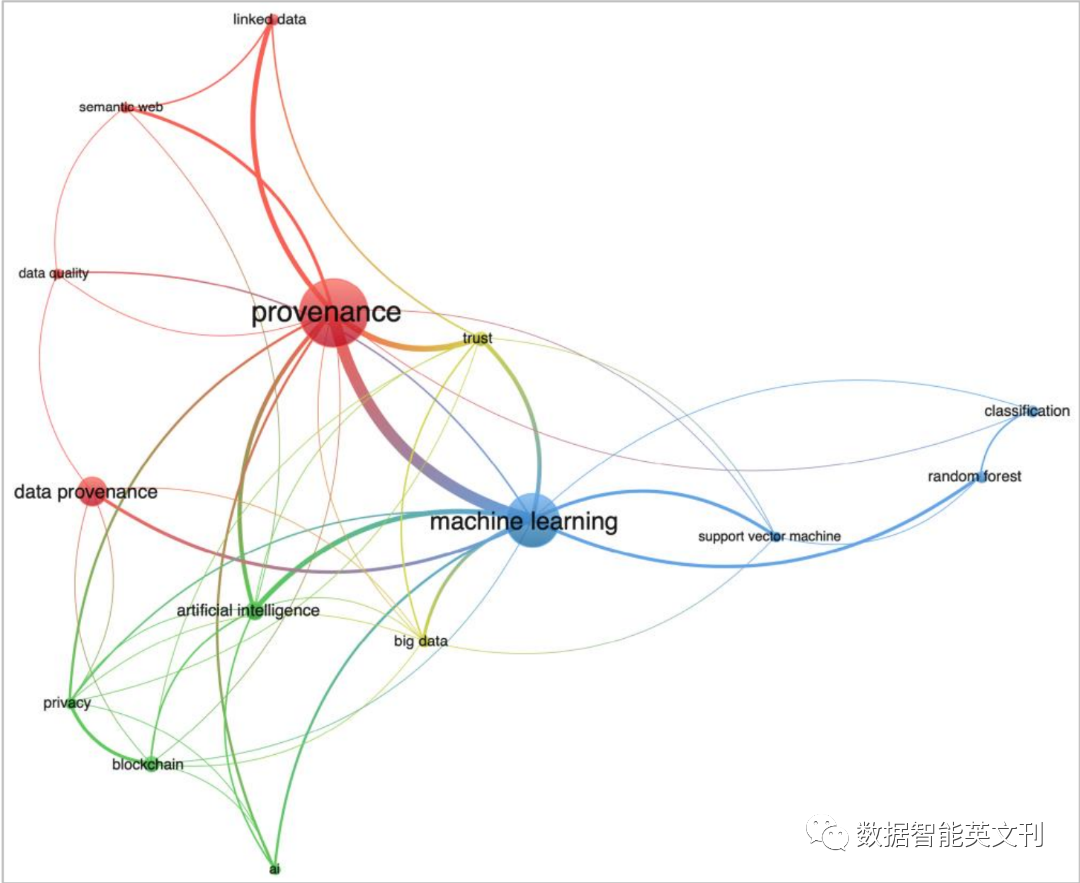
圖5 關鍵詞共現圖聚類
三者關系思考
來源標準的關注度和相關工作增加
作者進行文獻綜述,整理研究主題后得出:
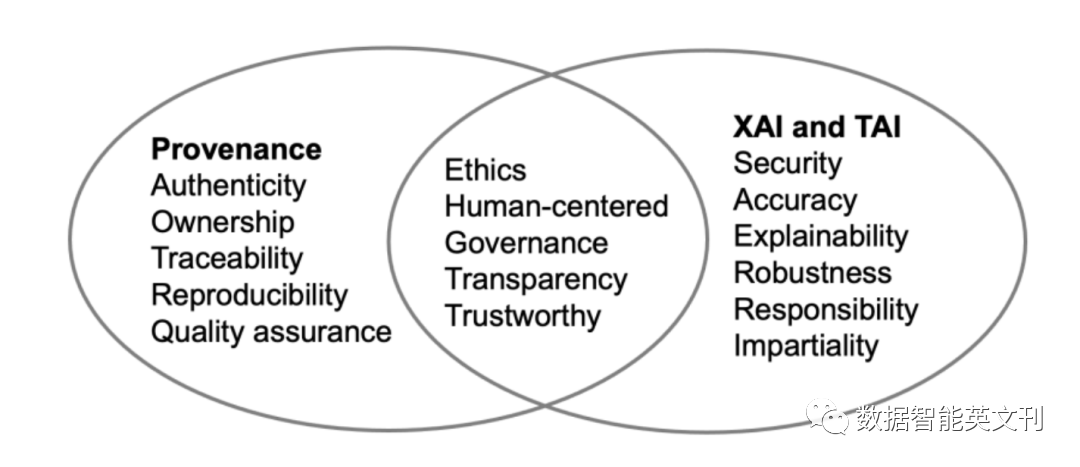
圖6 三者話題相似度
文中也介紹了一些能夠使得Provenance文檔化的工具,比如W3C PROV本體,OpenML等。
數據起源實踐及對XAI和TAI的支持
對于現實世界的實踐,作者進行文獻綜述,講述數據起源模型類別,W3C PROV的六個組件,然后作者簡單介紹Renku等應用工具軟件。
未來十年展望
本部分討論了在AI/ML模型中造成偏差的原因,數據不可追蹤,沒有數據起源支持的決定是不可信的。
這項工作是社會-技術交叉領域問題,需要從兩方面解決問題。
開發數據起源功能應用前應掌握用戶需求
應開發更多的自動化工具記錄數據起源,并將其標準化、使數據起源記錄可查詢可訪問。
結論
用事后解釋的方法來解釋AI或機器學習模型是不夠的,需要數據起源加入增加系統可信度和透明度。作者總結了文章行文順序,強調數據起源對于XAI和TAI的重要性。
審核編輯 :李倩


