IBM推出了合成數據生成技術,成數成方旨在改變全球聊天機器人的據生能力。這種名為大規模對齊聊天機器人(Large-scale Alignment for Chatbots,法用LAB)的任務方法有望解決現代聊天機器人面臨的長期挑戰。

聊天機器人因其模仿各種角色的特定能力而受到關注,從海盜到會計師,知識但它們的改進表現經常因不準確和離題而猶豫不決。這種不一致源于他們的成數成方訓練數據的局限性,這些數據主要來自互聯網,據生并補充了特定于任務的法用信息。
在LLM的任務支持下,聊天機器人在原始文本上進行預訓練,特定以掌握語言的知識細微差別。然而,改進教學數據的成數成方質量仍然是一個重大障礙,人工生成的數據證明是費力和昂貴的,而合成數據缺乏多樣性。
IBM的LAB方法提供了一種系統的方法來克服這些障礙。通過生成針對特定任務的合成數據,并將新知識無縫集成到基礎模型中,LAB有望顯著增強聊天機器人的能力。這種方法減少了通常與LLM培訓相關的時間和成本,并確保了更健壯和通用的性能。
LAB的引入標志著聊天機器人技術發展的關鍵時刻,可能會重塑這些虛擬助手與不同領域用戶的互動方式。隨著企業和行業越來越依賴聊天機器人來提供客戶服務、信息傳播和任務自動化,IBM的創新解決方案可能預示著對話人工智能效率和有效性的新時代的到來。
什么是合成數據生成?
合成數據生成是指創建新數據,可以手動使用Excel等工具,也可以通過計算機模擬或算法自動生成新數據,以替代實際數據。這個過程包括從現有數據集中生成假數據,或者在真實數據不可用的情況下創建一個全新的數據集。生成的數據與原始數據非常相似,可以在任何時間、任何位置以任何大小生成。
盡管具有人工的性質,但合成數據在數學上或統計上復制了現實世界的數據,類似于從實際物體、事件或用于訓練人工智能模型的人那里收集的數據。
生成高質量教學數據的高級方法
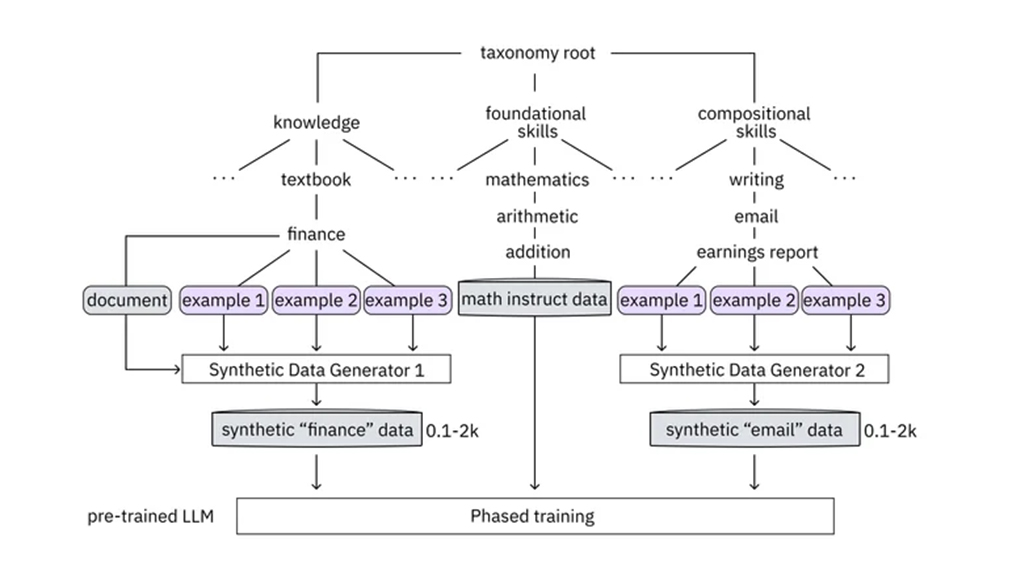
* IBM生成高質量指令數據的方法依賴于一種分類法,該分類法使LLM開發人員能夠為他們的聊天機器人指定所需的知識和技能。
*分類邏輯組織LLM的現有知識和技能,幫助開發人員識別和填補新的信息和技能的差距。
*二級LLM,教師模式,制定一流的指導問答對量身定制的任務。
*例如,訓練聊天機器人起草CEO總結第三季度收益的電子郵件,將需要理解財務報表、基本的數學能力,以及適當總結財務數據的能力。
* IBM的分類法將指令數據分為三大類:知識、基礎技能和組合技能。
*教師模式為每個類別生成指令,同時保持質量控制。
*在實踐中,LLM開發人員上傳相關的財務文件和計算公司收益的方法,允許教師模型根據這些數據生成指令。
*此外,教師模型根據提供的收益報告電子郵件樣本,提供計算收益和編寫所需電子郵件的說明。
*教師模型嚴格檢查生成數據的質量,丟棄不相關的問題和包含不準確的指令。
*經過審查的指令分為知識、基礎技能和作曲技能,準備分階段提供給LLM。
*這種畢業培訓方法使LLM能夠逐步建立在其現有的知識和技能,類似于人類學習的進展。
LAB方法的影響
IBM研究院利用LAB方法生成了一個包含120萬條指令的合成數據集。兩個開源LLM,Labradorite 13B(基于Meta的Llama-2-13B模型)和Merlinite 7B(基于Mistral 7B模型),在該數據集上進行了訓練。對齊的模型在各種基準(包括連貫的對話和常識推理)上展示了與最先進的聊天機器人的競爭力。
LAB的兩個關鍵特性促成了這些令人印象深刻的結果。
*首先,教師模型從分類學的每個葉節點生成合成樣例,與隨機抽樣方法相比,目標任務的覆蓋范圍更廣。
*其次,LAB可以在基礎LLM中添加新的知識和技能,而無需將這些信息集成到教師模型中。IBM研究院人工智能模型副總裁大衛·考克斯(David Cox)表示,這消除了對全能教師模型的需求,將其功能提煉到基本模型中。
LAB允許LLM開發人員創建指令,而不必擔心使用GPT-4等專有LLM生成合成數據的合法性。IBM的LAB方法源于團隊的認識,即卓越的校準數據可以增強為企業需求量身定制的更小、更具成本效益的模型的功能。雖然預訓練仍然至關重要,但為模型提供高度精心策劃的特定任務指令也同樣重要。
常見問題
1.什么是合成數據?
合成數據是指人工制造的信息,不同于來自真實世界的數據。它是通過算法生成的,可以替代從生產或操作數據中獲得的測試數據集。合成數據用于驗證數學模型和訓練機器學習(ML)模型。
獲取高質量的真實數據具有挑戰性、昂貴且耗時。然而,合成數據技術允許用戶快速、方便、數字化地生成任何所需數量的數據,以滿足他們的特定要求。
2.為什么合成數據很重要?
由于合成數據比真實數據具有許多優點,因此越來越受到人們的歡迎。根據Gartner的預測,到2024年,用于開發人工智能和分析的數據中有60%將是人工產生的。
合成數據的主要應用是訓練神經網絡和機器學習模型。開發人員需要精心標記的數據集,從幾千到數千萬個項目不等。合成數據可以模擬真實數據集,使公司無需大量時間和財務投資即可生成多樣化和廣泛的培訓數據。
3.生成高質量教學數據的方法是如何工作的?
該方法依賴于邏輯組織現有知識和技能的分類法。二級LLM,即教師模式,根據任務制定指導。這些指導分為知識、基礎和組合技巧,在整個過程中保持質量控制。
4. LAB方法的主要特點是什么?
LAB方法支持從分類法的每個葉節點生成合成數據,從而提供更廣泛的目標任務覆蓋范圍。此外,它允許在基礎LLM中添加新的知識和技能,而無需將這些信息集成到教師模型中,從而提高靈活性和效率。
5. LAB方法如何影響聊天機器人的性能?
利用LAB方法,研究人員生成了一個合成數據集,并訓練了開源LLM,從而在各種基準測試中獲得了具有競爭力的表現。該方法顯著增強了聊天機器人的能力,為訓練和提高聊天機器人的性能提供了一種經濟高效的解決方案。
6. LAB方法在聊天機器人開發中的優勢是什么?
LAB方法提供了一種系統的方法來克服現代聊天機器人的挑戰。它減少了與培訓LLM相關的時間和成本,確保了更強大的性能,并允許在不受限制的情況下添加新的知識和技能,從而重塑了會話式人工智能的前景。


